Last week, I attended the Numenta workshop. I didn't know much about Numenta before I went. My friend's excitement about the technology Numenta is building piqued my curiosity, so I decided to check it out. It seemed that almost everyone else in the conference had read Jeff Hawkins's On Intelligence and at least experimented with Numeta's tools, so I felt like a real n00b. I'm happy I went, though, because I learned about some interesting ideas and technologies.
Jeff Hawkins, Numenta's founder, has been fascinated with the workings of the brain throughout his career, but only two decades into it, after he founded Palm and Handspring, was he able to devote his efforts to artificial intelligence. In On Intelligence, Hawkins discusses his theories on the brain's functions in detail. Numenta, a company he founded with Dileep George and Donna Dubinsky, aims to put these ideas to work in commercial and research applications.
Numenta is a platform company. The platform they develop is NuPIC (Numenta Platform for Intelligent Computing), a software toolkit essentially for building pattern classifiers. The fundamental concept behind NuPIC is called HTM (Hierarchical Temporal Memory). It postulates that the cortex learns to recognize patterns using a combination of two basic algorithms: hierarchical belief propagation, and the detection of invariants in a sequence of transformations in time. I won't get into what this all means because there's plenty of documentation on the Numenta website. I recommend browsing it if you find this interesting.
HTM is not just theory. Although NuPIC is in a very early stage, companies are applying NuPIC to a wide range of problems, including vision, voice recognition, finance, motion recognition (recognizing motion capture data to detect if a person is walking, running, sitting, etc) and games. This is just a small subset of its potential uses.
Using Nupic in its current state isn't trivial. It provides the building blocks for HTM pattern classifiers, but application developers still have to do a good deal of work to tune the parameters of their HTM (How many nodes? How many levels in the hierarchy? How much training data to use? How many categories? What transformations to apply to the input over time to train the system?) to their problem domain. Also, some important features haven't been implemented yet. For example, although NuPIC can be pretty effective at classifying images that contain a single object against a plain background (with enough training), it isn't designed to recognize objects in images with noisy backgrounds or with multiple objects. (The problem of how to identify interesting objects in a scene is called the "attention" problem. To solve it you need to have a mechanism by which the top nodes could send feedback down to the bottom nodes. Hawkins said Numenta will tackle it in a future release.)
One reason I find Numenta so interesting is that I believe that NuPIC, or something like it, will play a role in the evolution of the Web. The current generation of web applications is effective at aggregating massive amounts of data in different verticals (pictures, videos, bookmarks, status messages, paintings), slicing and dicing it in different ways, searching it, and displaying it in an organized fashion. Mashups provide additional context for the data gathered in the different silos of the web (Kosmix is a good example), but they don't add any real "intelligence" to the mix, i.e. they don't extract new knowledge from the data they aggregate. Numenta's technology could be used to implement a new layer of intelligence on top of existing services by training it to recognize spacial and temporal pattens in the data they've collected. For example, imagine a Flickr API that let you submit an image and Flickr would tell you what the objects in the image are and where the picture was taken. Or a Facebook API for identifying the people in a picture. Or a Skype API for recognizing the speaker from a voice sample (creepy, I know). Or a HotOrNot API for automatically classifying the hotness of a person (ok, bad example :) ). Or a YouTube API for identifying the objects and events in a video clip. Or a icanhascheezburger API for automatically classifying the LOLness of a cat (well... maybe not :) ).
If this happens, maybe some day a mashup of these web services will be used to build something that resembles real AI. If (when?) someone manages to build a real-life WALL*E (great movie!), I think there's a good chance its HTMs will be trained on the vast amounts of data gathered on the web.
Sunday, June 29, 2008
Saturday, June 28, 2008
Twoorl Goes Multilingual
Since its launch, Twoorl users have helped translate it to Spanish, German, French, Korean, Polish, Portuguese (Brazilian) and Russian. This is an awesome contribution from the Twoorl community. Big thanks to everyone who contributed a translation!
If you're fluent in a language that Twoorl hasn't been translated into and you'd like to contribute a translation for it, obtain the file twoorl_eng.erl, translate the english strings, and email me the modified file. (Please make sure the file is encoded in UTF-8.) If you're familiar with Git, you can also clone the repository, make the changes, and send me a message through GitHub to pull your updates. Thanks in advance!
If you're fluent in a language that Twoorl hasn't been translated into and you'd like to contribute a translation for it, obtain the file twoorl_eng.erl, translate the english strings, and email me the modified file. (Please make sure the file is encoded in UTF-8.) If you're familiar with Git, you can also clone the repository, make the changes, and send me a message through GitHub to pull your updates. Thanks in advance!
Wednesday, May 28, 2008
Announcing Twoorl: an open source ErlyWeb-based Twitter clone
With the recent brouhaha over Twitter's scalability problems, I thought, wouldn't it be fun to write a Twitter clone in Erlang?
Last weekend was cold and rainy here in Palo Alto, so I sat down and hacked one, and thus Twoorl was born. It took me one full day plus a couple of evenings. The codebase is about 1700 lines (including comments). You can get it at http://code.google.com/p/twoorl
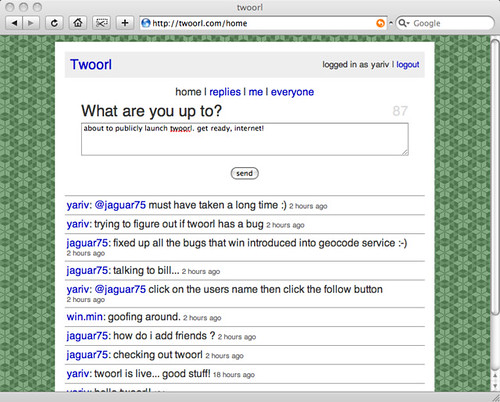
Note: you need the trunk version of ErlyWeb to make it work (when released, it will be the 0.7.1 version).
Many people written about Twitter's scalability problems and how to solve them. Some have blamed Rails (TechCrunch is among them), whereas others, including Blaine Cook, Twitter's Architect, have convincingly argued that you can scale a webapp written in any language/framework if you've figured out how to Just Add More Servers to handle the growing traffic. Eran Hammer-Lahav wrote some of the most insightful articles on the subject, On Scaling a Microblogging Service.
I have no idea why Twitter is having a hard time scaling. Well, I have some suspicions, but since I haven't been in the Twitter trenches, such speculation isn't worth wasting many pixels on.
I didn't write a Twitter clone in Erlang because I thought my implementation would be inherently more scalable than a Rails one (although it may be cheaper to scale because Erlang has very good performance) . In fact, Twoorl right now wouldn't scale well at all since I prioritized simplicity above all else.
The reasons I wrote Twoorl are:
- ErlyWeb needs more open source apps showing how to use the framework. It's hard to pick how to use the framework just from the API docs.
- Twitter is awesome. Once you start using it, it becomes addictive. I thought it would be fun to write my own.
- Twitter is very popular, but I don't know of any open source clones. I figured somebody may actually want one!
- Some people think Erlang isn't a good language for building webapps. I like to prove them wrong :)
- Although you can scale pretty much anything, your choice of language can make a difference in of performance and stability, both of which lead to happy users.
- I think Erlang is a great language for writing a Twitter clone because Twitter's functionality offers interesting opportunities benefit from concurrency. Here are a couple of ideas I thought of:
1) If you use sharding, the Tweets for different users would be stored in separated databases. When you render the page for someone's timeline, wouldn't it be advantageous to fetch the tweets for all the users she follows in parallel? In Ruby, you would probably do something like this:
(Please forgive any language errors -- my Ruby is very rusty. Treat the above as Pseudo code.).
This code would work well enough for a small number of tweet streams, but as the number gets large, it would take a very long time to execute.
In ErlyWeb, you could instead do the following:
This would spawn a process for each user the user follows, fetch the tweets for that user, then reassemble them in sorted order in the original process before rendering the page. (Think of it as map/reduce implemented directly in the application controller.) If a user follows hundreds of other users, querying their tweets in parallel can significantly reduce page rendering time.
2) Background tasks. When a user sends a tweet, the first thing you want to do is store it in the database. Then, depending on the features, you have to do a bunch of other stuff: send IM/SMS notifications, update RSS feeds, expire caches, etc. Why not do those tasks in different background processes? After to write to the DB, you can return an immediate reply to the user, giving him or her the perception of speed, and then let the background processes do all the extra work for processing the tweet.
(Such technique works very well for Facebook apps, by the way. In Vimagi, when the user submits a painting, the app first saves the painting data, and then it spawns a new process to update the news feed and profile box, send notifications, etc.)
Anyway, I hope you enjoy Twoorl. It's still in very early alpha. It doesn't have many features and it probably has bugs. Please take Twoorl for a spin and give me your feedback! I'll also appreciate useful contributions :)
Last weekend was cold and rainy here in Palo Alto, so I sat down and hacked one, and thus Twoorl was born. It took me one full day plus a couple of evenings. The codebase is about 1700 lines (including comments). You can get it at http://code.google.com/p/twoorl
Note: you need the trunk version of ErlyWeb to make it work (when released, it will be the 0.7.1 version).
Many people written about Twitter's scalability problems and how to solve them. Some have blamed Rails (TechCrunch is among them), whereas others, including Blaine Cook, Twitter's Architect, have convincingly argued that you can scale a webapp written in any language/framework if you've figured out how to Just Add More Servers to handle the growing traffic. Eran Hammer-Lahav wrote some of the most insightful articles on the subject, On Scaling a Microblogging Service.
I have no idea why Twitter is having a hard time scaling. Well, I have some suspicions, but since I haven't been in the Twitter trenches, such speculation isn't worth wasting many pixels on.
I didn't write a Twitter clone in Erlang because I thought my implementation would be inherently more scalable than a Rails one (although it may be cheaper to scale because Erlang has very good performance) . In fact, Twoorl right now wouldn't scale well at all since I prioritized simplicity above all else.
The reasons I wrote Twoorl are:
- ErlyWeb needs more open source apps showing how to use the framework. It's hard to pick how to use the framework just from the API docs.
- Twitter is awesome. Once you start using it, it becomes addictive. I thought it would be fun to write my own.
- Twitter is very popular, but I don't know of any open source clones. I figured somebody may actually want one!
- Some people think Erlang isn't a good language for building webapps. I like to prove them wrong :)
- Although you can scale pretty much anything, your choice of language can make a difference in of performance and stability, both of which lead to happy users.
- I think Erlang is a great language for writing a Twitter clone because Twitter's functionality offers interesting opportunities benefit from concurrency. Here are a couple of ideas I thought of:
1) If you use sharding, the Tweets for different users would be stored in separated databases. When you render the page for someone's timeline, wouldn't it be advantageous to fetch the tweets for all the users she follows in parallel? In Ruby, you would probably do something like this:
def get_tweets(users)
var alltweets = Array.new()
users.each { | user |
alltweets.add(user.fetch_tweets())
}
alltweets.sort()
return alltweets
end
(Please forgive any language errors -- my Ruby is very rusty. Treat the above as Pseudo code.).
This code would work well enough for a small number of tweet streams, but as the number gets large, it would take a very long time to execute.
In ErlyWeb, you could instead do the following:
get_tweets(Users) ->
sort(flatten(pmap(fun(Usr) -> Usr:tweets() end, Users)))
This would spawn a process for each user the user follows, fetch the tweets for that user, then reassemble them in sorted order in the original process before rendering the page. (Think of it as map/reduce implemented directly in the application controller.) If a user follows hundreds of other users, querying their tweets in parallel can significantly reduce page rendering time.
2) Background tasks. When a user sends a tweet, the first thing you want to do is store it in the database. Then, depending on the features, you have to do a bunch of other stuff: send IM/SMS notifications, update RSS feeds, expire caches, etc. Why not do those tasks in different background processes? After to write to the DB, you can return an immediate reply to the user, giving him or her the perception of speed, and then let the background processes do all the extra work for processing the tweet.
(Such technique works very well for Facebook apps, by the way. In Vimagi, when the user submits a painting, the app first saves the painting data, and then it spawns a new process to update the news feed and profile box, send notifications, etc.)
Anyway, I hope you enjoy Twoorl. It's still in very early alpha. It doesn't have many features and it probably has bugs. Please take Twoorl for a spin and give me your feedback! I'll also appreciate useful contributions :)
Sunday, May 18, 2008
Erlang vs. Scala
In my time wasting activities on geeky social news sites, I've been seeing more and more articles about Scala. The main reasons I became interested in Scala are 1) Scala is an OO/FP hybrid, and I think that any attempt to introduce more FP concepts into the OO world is a good thing and 2) Scala's Actors library is heavily influenced by Erlang, and Scala is sometimes mentioned in the same context as Erlang as a great language for building scalable concurrent applications.
A few times, I've seen the following take on the relative mertis of Scala and Erlang: Erlang is great for concurrent programming and it has a great track record in its niche, but it's unlikely to become mainstream because it's foreign and it doesn't have as many libraries as Java. Scala, on the hand, has the best of both worlds. Its has functional semantics, its Actors library provides Erlang style concurrency, and it runs on the JVM and it has access to all the Java libraries. This combination makes Scala it a better choice for building concurrent applications, especially for companies that are invested in Java.
I haven't coded in Scala, but I did a good amount of research on it and it looks like a great language. Some of the best programmers I know rave about it. I think that Scala can be a great replacement for Java. Function objects, type inference, mixins and pattern matching are all great language features that Scala has and that are sorely missing from Java.
Although I believe Scala is a great language that is clearly superior to Java, Scala doesn't supersede Erlang as my language of choice for building high-availability, low latency, massively concurrent applications. Scala's Actors library is a big improvement over what Java has to offer in terms of concurrency, but it doesn't provide all the benefits of Erlang-style concurrency that make Erlang such a great tool for the job. I did a good amount of research into the matter and these are the important differences I think one should consider when choosing between Scala and Erlang. (If I missed something or got something wrong, please let me know. I don't profess to be a Scala expert by any means.)
Scala's Actor library does a good job at emulating Erlang style message passing. Similar to Erlang processes, Scala actors send and receive messages through mailboxes. Like Erlang, Scala has pattern matching sematics for receiving messages, which results in elegant, concise code (although I think Erlang's simpler type system makes pattern matching easier in Erlang).
Scala's Actors library goes pretty far, but it doesn't (well, it can't) provide an important feature that makes concurrent programming so easy in Erlang: immutability. In Erlang, multiple processes can share the same data within the same VM, and the language guarantees that race conditions won't happen because this data is immutable. In Scala, though, you can send between actors pointers to mutable objects. This is the classic recipe for race conditions, and it leaves you just where you started: having to ensure synchronized access to shared memory.
If you're careful, you may be able to avoid this problem by copying all messages or by treating all sent objects as immutable, but the Scala language doesn't guarantee safe access to shared objects. Erlang does.
Hot code swapping it a killer feature. Not only does it (mostly) eliminates the downtime required to do code upgrades, it also makes a language much more productive because it allows for true interactive programming. With hot code swapping, you can immediately test the effects of code changes without stopping your server, recompiling your code, restarting your server (and losing the application's state), and going back to where you had been before the code change. Hot code swapping is one of the main reasons I like coding in Erlang.
The JVM has limited support for hot code swapping during development -- I believe it only lets you change a method's body at runtime (an improvement for this feature is in Sun's top 25 RFE's for Java). This capability is not as robust as Erlang's hot code swapping, which works for any code modification at any time.
A great aspect of Erlang's hot code swapping is that when you load new code, the VM keeps around the previous version of the code. This gives running processes an opportunity to receive a message to perform a code swap before the old version of the code is finally removed (which kills processes that didn't perform a code upgrade). This feature is unique to Erlang as far as I know.
Hot code swapping is even more important for real-time applications that enable synchronous communications between users. Restarting such servers would cause user sessions to disconnect, which would lead to poor user experience. Imagine playing World of Warcraft and, in the middle of a major battle, losing your connection because the developers wanted to add a log line somewhere in the code. It would be pretty upsetting.
A common argument against GC'd languages is that they are unsuitable for low latency applications due to potential long GC sweeps that freeze the VM. Modern GC optimizations such as generational collection alleviate the problem somewhat, but not entirely. Occasionally, the old generation needs to be collected, which can trigger long sweeps.
Erlang was designed for building applications that have (soft) real-time performance, and Erlang's garbage collection is optimized for this end. In Erlang, processes have separate heaps that are GC'd separately, which minimizes the time a process could freeze for garbage collection. Erlang also has ets, an in-memory storage facility for storing large amounts of data without any garbage collection (you can find more information on Erlang GC at http://prog21.dadgum.com/16.html).
Erlang might not have a decisive advantage here. The JVM has a new concurrent garbage collector designed to minimize freeze times. This article and this whitepaper (PDF warning) have some information about how it works. This collector trades performance and memory overhead for shorter freezes. I haven't found any benchmarks that show how well it works in production apps, though, and if it is as effective as Erlang's garbage collector for low-latency apps.
The Erlang VM schedules processes preemptively. Each process gets a certain number of reductions (roughly equivalent to function calls) before it's swapped out for another process. Erlang processes can't call blocking operations that freeze the scheduler for long periods. All file IO and communications with native libraries are done in separate OS threads (communications are done using ports). Similar to Erlang's per-process heaps, this design ensures that Erlang's lightweight processes can't block each other. The downside is some communications overhead due to data copying, but it's a worthwhile tradeoff.
Scala has two types of Actors: thread-based and event based. Thread based actors execute in heavyweight OS threads. They never block each other, but they don't scale to more than a few thousand actors per VM. Event-based actors are simple objects. They are very lightweight, and, like Erlang processes, you can spawn millions of them on a modern machine. The difference with Erlang processes is that within each OS thread, event based actors execute sequentially without preemptive scheduling. This makes it possible for an event-based actor to block its OS thread for a long period of time (perhaps indefinitely).
According to the Scala actors paper, the actors library also implements a unified model, by which event-based actors are executed in a thread pool, which the library automatically resizes if all threads are blocked due to long-running operations. This is pretty much the best you can do without runtime support, but it's not as robust as the Erlang implementation, which guarantees low latency and fair use of resources. In a degenerate case, all actors would call blocking operations, which would increase the native thread pool size to the point where it can't grow anymore beyond a few thousand threads.
This can't happen in Erlang. Erlang only allocates a fixed number of OS threads (typically, one per processor core). Idle processes don't impose any overhead on the scheduler. In addition, spawning Erlang processes is always a very cheap operation that happens very fast. I don't think the same applies to Scala when all existing threads are blocked, because this condition first needs to be detected, and then new OS threads need to be spawned to execute pending Actors. This can add significant latency (this is admittedly theoretical: only benchmarks can show the real impact).
Depends on what you're doing, the difference between process scheduling in Erlang and Scala may not impact performance much. However, I personally like knowing with certainty that the Erlang scheduler can gracefully handle pretty much anything I throw at it.
One of Erlang's greatest strengths is that it unifies concurrent and distributed programming. Erlang lets you send a message to a process in the local or on a remote VM using exactly the same semantics (this is sometimes referred to as "location transparency"). Furthermore, Erlang's process spawning and linking/monitoring works seamlessly across nodes. This takes much of the pain out of building distributed, fault-tolerant applications.
The Scala Actors library has a RemoteActor type that apparently provides the similar location-transparency, but I haven't been able to find much information about it. According to this article, it's also possible to distribute Scala actors using Terracotta, which does distributed memory voodoo between nodes in a JVM cluster, but I'm not sure how well it works or how simple it is to set up. In Erlang, everything works out of the box, and it's so simple to get it working it's in the language's Getting Started manual.
Lightweight concurrency with no shared memory and pure message passing semantics is a fantastic toolset for building concurrent applications... until you realize you need shared (transactional) memory. Imagine building a WoW server, where characters can buy and sell items between each other. This would be very hard to build without a transactional DBMS of sorts. This is exactly what Mnesia provides -- with the a number of extra benefits such as distributed storage, table fragmentation, no impedance mismatch, no GC overhead (due to ets), hot updates, live backups, and multiple disc/memory storage options (you can read the Mnesia docs for more info). I don't think Scala/Java has anything quite like Mnesia, so if you use Scala you have to find some alternative. You would probably have to use an external DBMS such as MySQL cluster, which may incur a higher overhead than a native solution that runs in the same VM.
Functional programming and recursion go hand-in-hand. In fact, you could hardly write working Erlang programs without tail recursion because Erlang doesn't have loops -- it uses recursion for *everything* (which I believe is a good thing :) ). Tail recursion serves for more than just style -- it's also facilitates hot code swapping. Erlang gen_servers call their loop() function recursively between calls to 'receive'. When a gen_server receive a code_change message, they can make it a remote call (e.g. Module:loop()) to re-enter its main loop with the new code. Without tail recursion, this style of programming would quickly result in stack overflows.
From my research, I learned that Scala has limited support for tail recursion due to bytecode restrictions in most JVMs. From http://www.scala-lang.org/docu/files/ScalaByExample.pdf:
(If I understand the limitation correctly, tail call optimization in Scala only works within the same function (i.e. x() can make a tail recursive call to x(), but if x() calls y(), y() couldn't make a tail recursive call back to x().)
In Erlang, tail recursion Just Works.
Erlang processes are tightly integrated with the Erlang VM's event-driven network IO core. Processes can "own" sockets and send and receive messages to/from sockets. This provides the elegance of concurrency-oriented programming plus the scalability of event-driven IO (the Erlang VM uses epoll/kqueue under the covers). From Googling around, I haven't found similar capabilities in Scala actors, although they may exist.
In Erlang, you can get a remote shell into any running VM. This allows you to analyzing the state of the VM at runtime. For example, you can check how many processes are running, how much memory they consume, what data is stored Mnesia, etc.
The remote shell is also a powerful tool for discovering bugs in your code. When the server is in a bad state, you don't always have to try to reproduce the bug offline somehow to devise a fix. You can log right into it and see what's wrong. If it's not obvious, you can make quick code changes to add more logging and then revert them when you've discovered the problem. I haven't found a similar feature in Scala/Java from some Googling. It probably wouldn't be too hard to implement a remote shell for Scala, but without hot code swapping it would be much less useful.
Scala runs on the JVM, it can easily call any Java library, and it is therefore closer than Erlang to many programmers' comfort zones. However, I think that Erlang is very easy to learn -- definitely easier than Scala, which contains a greater total number of concepts you need to know in order to use the language effectively (especially if you consider the Java foundations on which Scala is built). This is to a large degree due to Erlang's dynamic typing and lack of object orientation. I personally prefer Erlang's more minimalist style, but this is a subjective matter and I don't want to get into religious debates here :)
Java indeed has a lot of libraries -- many more than Erlang. However, this doesn't mean that Erlang has no batteries included. In fact, Erlang's libraries are quite sufficient for many applications (you'll have to decide for yourself if they are sufficient for you). If you really need to use a Java library that doesn't have an Erlang equivalent, you could call it using Jinterface. It may or may not be a suitable option for your application. This can indeed be a deal breaker for some people who are deciding between the two languages.
There's an important difference between Java/Scala and Erlang libraries besides their relative abundance: virtually all "big" Erlang libraries use Erlang's features concurrency and fault tolerance. In the Erlang ecosystem, you can get web servers, database connection pools, XMPP servers, database servers, all of which use Erlang's lightweight concurrency, fault tolerance, etc. Most of Scala's libraries, on the other hand, are written in Java and they don't use Scala actors. It will take Scala some time to catch up to Erlang in the availability of libraries based on Actors.
Erlang has been running massive systems for 20 years. Erlang-powered phone switches have been running with nine nines availability -- only 31ms downtime per year. Erlang also scales. From telcom apps to Facebook Chat we have enough evidence that Erlang works as advertised. Scala on the other hand is a relatively new language and as far as I know its actors implementation hasn't been tested in large-scale real-time systems.
I hope I did justice to Scala and Erlang in this comparison (which, by the way, took me way too much to write!). Regardless of these differences, though, I think that Scala has a good chance of being the more popular language of the two. Steve Yegge explains it better than I can:
Well, at least I'm not trying too hard to promote LFE... :)
A few times, I've seen the following take on the relative mertis of Scala and Erlang: Erlang is great for concurrent programming and it has a great track record in its niche, but it's unlikely to become mainstream because it's foreign and it doesn't have as many libraries as Java. Scala, on the hand, has the best of both worlds. Its has functional semantics, its Actors library provides Erlang style concurrency, and it runs on the JVM and it has access to all the Java libraries. This combination makes Scala it a better choice for building concurrent applications, especially for companies that are invested in Java.
I haven't coded in Scala, but I did a good amount of research on it and it looks like a great language. Some of the best programmers I know rave about it. I think that Scala can be a great replacement for Java. Function objects, type inference, mixins and pattern matching are all great language features that Scala has and that are sorely missing from Java.
Although I believe Scala is a great language that is clearly superior to Java, Scala doesn't supersede Erlang as my language of choice for building high-availability, low latency, massively concurrent applications. Scala's Actors library is a big improvement over what Java has to offer in terms of concurrency, but it doesn't provide all the benefits of Erlang-style concurrency that make Erlang such a great tool for the job. I did a good amount of research into the matter and these are the important differences I think one should consider when choosing between Scala and Erlang. (If I missed something or got something wrong, please let me know. I don't profess to be a Scala expert by any means.)
Concurrent programming
Scala's Actor library does a good job at emulating Erlang style message passing. Similar to Erlang processes, Scala actors send and receive messages through mailboxes. Like Erlang, Scala has pattern matching sematics for receiving messages, which results in elegant, concise code (although I think Erlang's simpler type system makes pattern matching easier in Erlang).
Scala's Actors library goes pretty far, but it doesn't (well, it can't) provide an important feature that makes concurrent programming so easy in Erlang: immutability. In Erlang, multiple processes can share the same data within the same VM, and the language guarantees that race conditions won't happen because this data is immutable. In Scala, though, you can send between actors pointers to mutable objects. This is the classic recipe for race conditions, and it leaves you just where you started: having to ensure synchronized access to shared memory.
If you're careful, you may be able to avoid this problem by copying all messages or by treating all sent objects as immutable, but the Scala language doesn't guarantee safe access to shared objects. Erlang does.
Hot code swapping
Hot code swapping it a killer feature. Not only does it (mostly) eliminates the downtime required to do code upgrades, it also makes a language much more productive because it allows for true interactive programming. With hot code swapping, you can immediately test the effects of code changes without stopping your server, recompiling your code, restarting your server (and losing the application's state), and going back to where you had been before the code change. Hot code swapping is one of the main reasons I like coding in Erlang.
The JVM has limited support for hot code swapping during development -- I believe it only lets you change a method's body at runtime (an improvement for this feature is in Sun's top 25 RFE's for Java). This capability is not as robust as Erlang's hot code swapping, which works for any code modification at any time.
A great aspect of Erlang's hot code swapping is that when you load new code, the VM keeps around the previous version of the code. This gives running processes an opportunity to receive a message to perform a code swap before the old version of the code is finally removed (which kills processes that didn't perform a code upgrade). This feature is unique to Erlang as far as I know.
Hot code swapping is even more important for real-time applications that enable synchronous communications between users. Restarting such servers would cause user sessions to disconnect, which would lead to poor user experience. Imagine playing World of Warcraft and, in the middle of a major battle, losing your connection because the developers wanted to add a log line somewhere in the code. It would be pretty upsetting.
Garbage collection
A common argument against GC'd languages is that they are unsuitable for low latency applications due to potential long GC sweeps that freeze the VM. Modern GC optimizations such as generational collection alleviate the problem somewhat, but not entirely. Occasionally, the old generation needs to be collected, which can trigger long sweeps.
Erlang was designed for building applications that have (soft) real-time performance, and Erlang's garbage collection is optimized for this end. In Erlang, processes have separate heaps that are GC'd separately, which minimizes the time a process could freeze for garbage collection. Erlang also has ets, an in-memory storage facility for storing large amounts of data without any garbage collection (you can find more information on Erlang GC at http://prog21.dadgum.com/16.html).
Erlang might not have a decisive advantage here. The JVM has a new concurrent garbage collector designed to minimize freeze times. This article and this whitepaper (PDF warning) have some information about how it works. This collector trades performance and memory overhead for shorter freezes. I haven't found any benchmarks that show how well it works in production apps, though, and if it is as effective as Erlang's garbage collector for low-latency apps.
Scheduling
The Erlang VM schedules processes preemptively. Each process gets a certain number of reductions (roughly equivalent to function calls) before it's swapped out for another process. Erlang processes can't call blocking operations that freeze the scheduler for long periods. All file IO and communications with native libraries are done in separate OS threads (communications are done using ports). Similar to Erlang's per-process heaps, this design ensures that Erlang's lightweight processes can't block each other. The downside is some communications overhead due to data copying, but it's a worthwhile tradeoff.
Scala has two types of Actors: thread-based and event based. Thread based actors execute in heavyweight OS threads. They never block each other, but they don't scale to more than a few thousand actors per VM. Event-based actors are simple objects. They are very lightweight, and, like Erlang processes, you can spawn millions of them on a modern machine. The difference with Erlang processes is that within each OS thread, event based actors execute sequentially without preemptive scheduling. This makes it possible for an event-based actor to block its OS thread for a long period of time (perhaps indefinitely).
According to the Scala actors paper, the actors library also implements a unified model, by which event-based actors are executed in a thread pool, which the library automatically resizes if all threads are blocked due to long-running operations. This is pretty much the best you can do without runtime support, but it's not as robust as the Erlang implementation, which guarantees low latency and fair use of resources. In a degenerate case, all actors would call blocking operations, which would increase the native thread pool size to the point where it can't grow anymore beyond a few thousand threads.
This can't happen in Erlang. Erlang only allocates a fixed number of OS threads (typically, one per processor core). Idle processes don't impose any overhead on the scheduler. In addition, spawning Erlang processes is always a very cheap operation that happens very fast. I don't think the same applies to Scala when all existing threads are blocked, because this condition first needs to be detected, and then new OS threads need to be spawned to execute pending Actors. This can add significant latency (this is admittedly theoretical: only benchmarks can show the real impact).
Depends on what you're doing, the difference between process scheduling in Erlang and Scala may not impact performance much. However, I personally like knowing with certainty that the Erlang scheduler can gracefully handle pretty much anything I throw at it.
Distributed programming
One of Erlang's greatest strengths is that it unifies concurrent and distributed programming. Erlang lets you send a message to a process in the local or on a remote VM using exactly the same semantics (this is sometimes referred to as "location transparency"). Furthermore, Erlang's process spawning and linking/monitoring works seamlessly across nodes. This takes much of the pain out of building distributed, fault-tolerant applications.
The Scala Actors library has a RemoteActor type that apparently provides the similar location-transparency, but I haven't been able to find much information about it. According to this article, it's also possible to distribute Scala actors using Terracotta, which does distributed memory voodoo between nodes in a JVM cluster, but I'm not sure how well it works or how simple it is to set up. In Erlang, everything works out of the box, and it's so simple to get it working it's in the language's Getting Started manual.
Mnesia
Lightweight concurrency with no shared memory and pure message passing semantics is a fantastic toolset for building concurrent applications... until you realize you need shared (transactional) memory. Imagine building a WoW server, where characters can buy and sell items between each other. This would be very hard to build without a transactional DBMS of sorts. This is exactly what Mnesia provides -- with the a number of extra benefits such as distributed storage, table fragmentation, no impedance mismatch, no GC overhead (due to ets), hot updates, live backups, and multiple disc/memory storage options (you can read the Mnesia docs for more info). I don't think Scala/Java has anything quite like Mnesia, so if you use Scala you have to find some alternative. You would probably have to use an external DBMS such as MySQL cluster, which may incur a higher overhead than a native solution that runs in the same VM.
Tail recursion
Functional programming and recursion go hand-in-hand. In fact, you could hardly write working Erlang programs without tail recursion because Erlang doesn't have loops -- it uses recursion for *everything* (which I believe is a good thing :) ). Tail recursion serves for more than just style -- it's also facilitates hot code swapping. Erlang gen_servers call their loop() function recursively between calls to 'receive'. When a gen_server receive a code_change message, they can make it a remote call (e.g. Module:loop()) to re-enter its main loop with the new code. Without tail recursion, this style of programming would quickly result in stack overflows.
From my research, I learned that Scala has limited support for tail recursion due to bytecode restrictions in most JVMs. From http://www.scala-lang.org/docu/files/ScalaByExample.pdf:
In principle, tail calls can always re-use the stack frame of the calling function. However, some run-time environments (such as the Java VM) lack the primitives to make stack frame re-use for tail calls efficient. A production quality Scala implementation is therefore only required to re-use the stack frame of a directly tail-recursive function whose last action is a call to itself. Other tail calls might be optimized also, but one should not rely on this across implementations.
(If I understand the limitation correctly, tail call optimization in Scala only works within the same function (i.e. x() can make a tail recursive call to x(), but if x() calls y(), y() couldn't make a tail recursive call back to x().)
In Erlang, tail recursion Just Works.
Network IO
Erlang processes are tightly integrated with the Erlang VM's event-driven network IO core. Processes can "own" sockets and send and receive messages to/from sockets. This provides the elegance of concurrency-oriented programming plus the scalability of event-driven IO (the Erlang VM uses epoll/kqueue under the covers). From Googling around, I haven't found similar capabilities in Scala actors, although they may exist.
Remote shell
In Erlang, you can get a remote shell into any running VM. This allows you to analyzing the state of the VM at runtime. For example, you can check how many processes are running, how much memory they consume, what data is stored Mnesia, etc.
The remote shell is also a powerful tool for discovering bugs in your code. When the server is in a bad state, you don't always have to try to reproduce the bug offline somehow to devise a fix. You can log right into it and see what's wrong. If it's not obvious, you can make quick code changes to add more logging and then revert them when you've discovered the problem. I haven't found a similar feature in Scala/Java from some Googling. It probably wouldn't be too hard to implement a remote shell for Scala, but without hot code swapping it would be much less useful.
Simplicity
Scala runs on the JVM, it can easily call any Java library, and it is therefore closer than Erlang to many programmers' comfort zones. However, I think that Erlang is very easy to learn -- definitely easier than Scala, which contains a greater total number of concepts you need to know in order to use the language effectively (especially if you consider the Java foundations on which Scala is built). This is to a large degree due to Erlang's dynamic typing and lack of object orientation. I personally prefer Erlang's more minimalist style, but this is a subjective matter and I don't want to get into religious debates here :)
Libraries
Java indeed has a lot of libraries -- many more than Erlang. However, this doesn't mean that Erlang has no batteries included. In fact, Erlang's libraries are quite sufficient for many applications (you'll have to decide for yourself if they are sufficient for you). If you really need to use a Java library that doesn't have an Erlang equivalent, you could call it using Jinterface. It may or may not be a suitable option for your application. This can indeed be a deal breaker for some people who are deciding between the two languages.
There's an important difference between Java/Scala and Erlang libraries besides their relative abundance: virtually all "big" Erlang libraries use Erlang's features concurrency and fault tolerance. In the Erlang ecosystem, you can get web servers, database connection pools, XMPP servers, database servers, all of which use Erlang's lightweight concurrency, fault tolerance, etc. Most of Scala's libraries, on the other hand, are written in Java and they don't use Scala actors. It will take Scala some time to catch up to Erlang in the availability of libraries based on Actors.
Reliability and scalability
Erlang has been running massive systems for 20 years. Erlang-powered phone switches have been running with nine nines availability -- only 31ms downtime per year. Erlang also scales. From telcom apps to Facebook Chat we have enough evidence that Erlang works as advertised. Scala on the other hand is a relatively new language and as far as I know its actors implementation hasn't been tested in large-scale real-time systems.
Conclusion
I hope I did justice to Scala and Erlang in this comparison (which, by the way, took me way too much to write!). Regardless of these differences, though, I think that Scala has a good chance of being the more popular language of the two. Steve Yegge explains it better than I can:
Scala might have a chance. There's a guy giving a talk right down the hall about it, the inventor of – one of the inventors of Scala. And I think it's a great language and I wish him all the success in the world. Because it would be nice to have, you know, it would be nice to have that as an alternative to Java.
But when you're out in the industry, you can't. You get lynched for trying to use a language that the other engineers don't know. Trust me. I've tried it. I don't know how many of you guys here have actually been out in the industry, but I was talking about this with my intern. I was, and I think you [(point to audience member)] said this in the beginning: this is 80% politics and 20% technology, right? You know.
And [my intern] is, like, "well I understand the argument" and I'm like "No, no, no! You've never been in a company where there's an engineer with a Computer Science degree and ten years of experience, an architect, who's in your face screaming at you, with spittle flying on you, because you suggested using, you know... D. Or Haskell. Or Lisp, or Erlang, or take your pick."
Well, at least I'm not trying too hard to promote LFE... :)
Wednesday, May 14, 2008
Is Facebook running one of the world's biggest Erlang clusters?
I just read on the Facebook engineering blog this post describing how Facebook used Erlang to scale Facebook Chat to 70 million active users overnight. WOW.
This announcement should remove any doubts that Erlang is *the* platform for building scalable realtime (aka Comet) applications.
This announcement should remove any doubts that Erlang is *the* platform for building scalable realtime (aka Comet) applications.
Monday, May 12, 2008
Erlang does have shared memory
I occasionally hear people say things such as "Erlang makes concurrency easy because it doesn't have shared memory" or "processes in Erlang communicate just by message passing." Just earlier today I came across one such comment on Steve Yegge's post Dynamic Languages Strike Back (you'll have some scrolling down to do -- it's a long article :) ).
For many purposes, it's "good enough" to think of Erlang as lacking shared memory. Erlang's built-in message passing semantics makes inter-process communications trivial to implement, and for many concurrent applications, it's all you need. Also, when you first learn Erlang, it's easy to get excited by the promise of not having to worry about the difficult shared memory problems you encounter in "traditional" concurrent programming. And that's for a good reason: Erlang indeed makes concurrent programming much easier (and more scalable, reliable, etc) than other languages. However, it's not true that Erlang processes can't share memory.
Erlang has (a kind of) shared memory: it's called ets.
From the ets documentation:
Multiple Erlang processes can simultaneously access and manipulate an ets table, which makes ets act very much like shared memory. ets isn't identical to shared memory in other languages, however. These are the main differences:
- Objects are copied when inserted into and looked-up from ets tables.
- Basic consistency is guaranteed. Individual ets records never get garbled.
- ets tables are not garbage collected (this lets you store massive amounts of data in RAM without incurring garbage collection penalties -- an important trait for soft real time performance.)
Despite these differences, as far as the programmer is concerned, ets is effectively shared memory. If you want to guarantee that multiple processes get a consistent snapshot of a set of objects in a plain ets table, you're out of luck.
The good news is that Erlang doesn't leave you to your own devices to figure out some subtle solution involving locking around critical regions to access ets tables safely from multiple processes. Instead, it provides a very nice tool for working with ets: Mnesia. Mnesia is is a kind of STM for Erlang, with some extra properties such as support for distributed and persistent storage. Mnesia has a simple transaction API you can use to ensure atomicity, isolation and consistency when accessing objects in an ets table.
Here's an example, taken for the Mnesia documentation, of how to raise an employee's salary in a transaction:
So, Erlang has shared memory, and it also has Mnesia, which provides easy transactional access to ets. Does that mean that concurrent programming in Erlang is just like other languages, but with using Mnesia for storing shared data? Not exactly. When you program in Erlang, you still use message passing in many situations where in other languages you would rely on semaphors/locks/monitors/signals/etc to enable inter-thread communications. In the simplest possible example, a producer/consumer application, you would use messaging in Erlang, not ets. In most other languages, you would probably use monitors to protect against concurrent access to a shared buffer (see the wikipedia examples).
Erlang isn't the only language that has message queues. In fact, you could use the basic concurrency facilities in most languages to implement message queues as higher-level abstractions for inter-thread communications (although you probably wouldn't be able to replicate Erlang's selective receive using pattern matching, and it probably wouldn't scale or perform as well as Erlang). This is exactly what some of the actor libraries out there do. However, you would have to be very careful to not send pointers/references to objects that would end up being shared between threads, or you would potentially run into nasty bugs when multiple threads modify the same object. In Erlang, all data is immutable, which makes such bugs impossible. And if even you figure out how to ensure copy semantics for message passing, you would still have your work cut out for you to allow processes to communicate between VMs...
Implementing full Erlang style concurrency isn't trivial. I don't think it can be added as a library to a language that doesn't have it by design with support from the runtime.
Erlang takes you as close as possible to concurrent (and distributed!) programming bliss -- but it does have (a kind of) shared memory: ets.
For many purposes, it's "good enough" to think of Erlang as lacking shared memory. Erlang's built-in message passing semantics makes inter-process communications trivial to implement, and for many concurrent applications, it's all you need. Also, when you first learn Erlang, it's easy to get excited by the promise of not having to worry about the difficult shared memory problems you encounter in "traditional" concurrent programming. And that's for a good reason: Erlang indeed makes concurrent programming much easier (and more scalable, reliable, etc) than other languages. However, it's not true that Erlang processes can't share memory.
Erlang has (a kind of) shared memory: it's called ets.
From the ets documentation:
This module provides very limited support for concurrent updates. No locking is available, but the safe_fixtable/2 function can be used to guarantee that a sequence of first/1 and next/2 calls will traverse the table without errors and that each object in the table is visited exactly once, even if another process (or the same process) simultaneously deletes or inserts objects into the table. Nothing more is guaranteed; in particular any object inserted during a traversal may be visited in the traversal.
Multiple Erlang processes can simultaneously access and manipulate an ets table, which makes ets act very much like shared memory. ets isn't identical to shared memory in other languages, however. These are the main differences:
- Objects are copied when inserted into and looked-up from ets tables.
- Basic consistency is guaranteed. Individual ets records never get garbled.
- ets tables are not garbage collected (this lets you store massive amounts of data in RAM without incurring garbage collection penalties -- an important trait for soft real time performance.)
Despite these differences, as far as the programmer is concerned, ets is effectively shared memory. If you want to guarantee that multiple processes get a consistent snapshot of a set of objects in a plain ets table, you're out of luck.
The good news is that Erlang doesn't leave you to your own devices to figure out some subtle solution involving locking around critical regions to access ets tables safely from multiple processes. Instead, it provides a very nice tool for working with ets: Mnesia. Mnesia is is a kind of STM for Erlang, with some extra properties such as support for distributed and persistent storage. Mnesia has a simple transaction API you can use to ensure atomicity, isolation and consistency when accessing objects in an ets table.
Here's an example, taken for the Mnesia documentation, of how to raise an employee's salary in a transaction:
raise(Eno, Raise) ->
F = fun() ->
[E] = mnesia:read(employee, Eno, write),
Salary = E#employee.salary + Raise,
New = E#employee{salary = Salary},
mnesia:write(New)
end,
mnesia:transaction(F).
So, Erlang has shared memory, and it also has Mnesia, which provides easy transactional access to ets. Does that mean that concurrent programming in Erlang is just like other languages, but with using Mnesia for storing shared data? Not exactly. When you program in Erlang, you still use message passing in many situations where in other languages you would rely on semaphors/locks/monitors/signals/etc to enable inter-thread communications. In the simplest possible example, a producer/consumer application, you would use messaging in Erlang, not ets. In most other languages, you would probably use monitors to protect against concurrent access to a shared buffer (see the wikipedia examples).
Erlang isn't the only language that has message queues. In fact, you could use the basic concurrency facilities in most languages to implement message queues as higher-level abstractions for inter-thread communications (although you probably wouldn't be able to replicate Erlang's selective receive using pattern matching, and it probably wouldn't scale or perform as well as Erlang). This is exactly what some of the actor libraries out there do. However, you would have to be very careful to not send pointers/references to objects that would end up being shared between threads, or you would potentially run into nasty bugs when multiple threads modify the same object. In Erlang, all data is immutable, which makes such bugs impossible. And if even you figure out how to ensure copy semantics for message passing, you would still have your work cut out for you to allow processes to communicate between VMs...
Implementing full Erlang style concurrency isn't trivial. I don't think it can be added as a library to a language that doesn't have it by design with support from the runtime.
Erlang takes you as close as possible to concurrent (and distributed!) programming bliss -- but it does have (a kind of) shared memory: ets.
Sunday, April 20, 2008
Startup School
I attended startup school on Saturday. It was a great experience and a rare opportunity to hear to a such impressive speakers share their wisdom about technology and entrepreneurship. Some of my favorite talks were by David Heinemeier Hansson, Greg McAdoo, Marc Andreesen, Paul Buchheit and Michael Arrington. I met a bunch of programmers and entrepreneurs and I also chatted briefly with DHH about 37signals and Peter Norvig about new search startups and their chances of competing with Google. Many thanks to YCombinator for organizing such a great event!
If you haven't attended, you can see all the videos here. Highly recommended.
If you haven't attended, you can see all the videos here. Highly recommended.
Monday, April 14, 2008
Concurrency and expressiveness
Damien Katz's article Lisp as Blub has sparked a lively debate on Hacker News on the relative merits of Erlang and other languages for building robust applications. Good points were made on all sides (except for the tired complaints about Erlang syntax -- I have a suspicion that most people who complain about it haven't done much coding in Erlang). Unfortunately, I think that a key point was lost in all the noise: all else being equal, a language with great support for concurrency and fault tolerance has a higher expressive power than a language that doesn't. It just lets you build concurrent applications much more easily (less code, fewer bugs, better scalability, yadda yadda).
Sunday, April 13, 2008
EC2 gets persistent block level storage
I just caught Amazon's announcement of the new persistent storage engine for EC2. This is great stuff. It lets you create persistent block level storage devices ranging from 1GB to 1TB in size and attach them to EC2 instances in predetermined availability zones. This service complements Amazon's other storage services -- EC2 and SimpleDB -- in providing raw block-level storage devices that are persistent, fast and local (so you don't have to worry about SimpleDB's eventual consistency issues). You can use these volumes for anything -- running a traditional DBMS (MySQL, Postgres) is the first thing that comes to mind.
This announcement is a departure from Amazon's tradition of announcing services only once they become available. It looks like Amazon is feeling the heat of competition from Google App Engine and is becoming more open to win over the hearts and minds of developers who are drawn to GAE for its auto-magical scalability. The ability to attach multiple terabyte-sized volumes on demand alleviates some of those concerns when deploying on Amazon's infrastructure. I'm sure it won't be long before someone creates an open source BigTable-like solution for applications that need massive scalability and redundancy on top of multiple persistent storage volumes (I think this would be a great application to write in Erlang, but I don't know how well Erlang performs in applications that require heavy disc IO).
I like what Amazon is doing. By providing the basic building blocks for scalable applications, its enables startups to create their own GAE competitors (Heroku is the first one that comes to mind) on top of Amazon's infrastructure. Smart move.
Google has the advantage of being able to provide APIs for tight integration with other Google services such as authentication and search (the latter is hypothetical as of now). We'll see how strongly this plays in Google's favor in the coming months.
Of course, price is still a question mark. Neither Amazon's persistent storage service nor GAE have had their prices announced.
Another missing detail is the Amazon store service's reliability. If a disc fails, do you lose your data? What's the failure probability? Etc.
All this is great for developers. Competition between Amazon and Google means developers will enjoy more services and for lower prices in the coming years.
This announcement is a departure from Amazon's tradition of announcing services only once they become available. It looks like Amazon is feeling the heat of competition from Google App Engine and is becoming more open to win over the hearts and minds of developers who are drawn to GAE for its auto-magical scalability. The ability to attach multiple terabyte-sized volumes on demand alleviates some of those concerns when deploying on Amazon's infrastructure. I'm sure it won't be long before someone creates an open source BigTable-like solution for applications that need massive scalability and redundancy on top of multiple persistent storage volumes (I think this would be a great application to write in Erlang, but I don't know how well Erlang performs in applications that require heavy disc IO).
I like what Amazon is doing. By providing the basic building blocks for scalable applications, its enables startups to create their own GAE competitors (Heroku is the first one that comes to mind) on top of Amazon's infrastructure. Smart move.
Google has the advantage of being able to provide APIs for tight integration with other Google services such as authentication and search (the latter is hypothetical as of now). We'll see how strongly this plays in Google's favor in the coming months.
Of course, price is still a question mark. Neither Amazon's persistent storage service nor GAE have had their prices announced.
Another missing detail is the Amazon store service's reliability. If a disc fails, do you lose your data? What's the failure probability? Etc.
All this is great for developers. Competition between Amazon and Google means developers will enjoy more services and for lower prices in the coming years.
Tag cloud in ErlyWeb howto
Nick Gerakines wrote a good tutorial on how to make tag clouds in ErlyWeb. Check it out at http://blog.socklabs.com/2008/04/tag_clouds_in_erlang_with_erly/.
Tuesday, April 01, 2008
ErlyWeb renamed "Erlang on Rails"
Erlang is *almost* a tipping point. Thanks to reddit, many people are interested in it. However, it's not there yet. Despite being the only language that got concurrency right, and all its other standout features, many developers still use other languages. The only explanation I can think of is that Erlang hasn't had much PR over the years (the Erlang movie nonwithstanding). I'm confident that a good PR boost will help push Erlang over the hill. Unfortunately, Ericsson doesn't seem interested in heavily promoting Erlang the way Microsoft promotes .NET and Sun promotes Java (this may be because many Ericsson employees have never heard of Erlang). So, I decided to take things into my own hands. I don't have a budget, so I need to get creative. The best way to succeed if you're small is to ride a big wave -- and what's a better wave to ride than Ruby on Rails?
Ruby on Rails is very popular -- much more than ErlyWeb. I believe this popularity is due to the "on Rails" meme, which is just bursting with positive connotations. It sounds young, fresh, happy. It's the anti-enterprisy software. It emancipates you from burdensome type systems, explicit getters and setters, and (ugh) XML. Its metaprogramming wizardry is made of bliss. Its evokes images of riding in environmentally-friendly transportation looking out the window at grassy meadows, rolling hills and sunny skies.
I think that renaming ErlyWeb to "Erlang on Rails" will help win over the hearts and minds of many programmers who are currently on the fence. They may be curious about Erlang but are turned off by its telcom image. "Erlang on Rails" conveys a more balanced feeling of industrial strength applications from the telcom world mixed with the social Web 2.0 era of interconnectedness that celebrates the rise of individualism over grey corporate culture.
2008 will be the year of Erlang on Rails. I know it.
Update: This was an April Fool's joke, in case it's not obvious anymore :)
Ruby on Rails is very popular -- much more than ErlyWeb. I believe this popularity is due to the "on Rails" meme, which is just bursting with positive connotations. It sounds young, fresh, happy. It's the anti-enterprisy software. It emancipates you from burdensome type systems, explicit getters and setters, and (ugh) XML. Its metaprogramming wizardry is made of bliss. Its evokes images of riding in environmentally-friendly transportation looking out the window at grassy meadows, rolling hills and sunny skies.
I think that renaming ErlyWeb to "Erlang on Rails" will help win over the hearts and minds of many programmers who are currently on the fence. They may be curious about Erlang but are turned off by its telcom image. "Erlang on Rails" conveys a more balanced feeling of industrial strength applications from the telcom world mixed with the social Web 2.0 era of interconnectedness that celebrates the rise of individualism over grey corporate culture.
2008 will be the year of Erlang on Rails. I know it.
Update: This was an April Fool's joke, in case it's not obvious anymore :)
Monday, March 31, 2008
Announcing the Erlang FriendFeed API
I just hacked together an (alpha) implementation of the FriendFeed API for Erlang. You can get the code at http://code.google.com/p/erlang-friendfeed/. Enjoy!
By the way, my shiny new FriendFeed is at http://friendfeed.com/yariv.
By the way, my shiny new FriendFeed is at http://friendfeed.com/yariv.
Sunday, March 23, 2008
I Play WoW: A Cool Facebook App Built With ErlyWeb
Nick Gerakines, the Author of Facebook Application Development, created with ErlyWeb the very cool Facebook app I Play WoW. I Play WoW bridges between real people and the characters they play on World of Warcraft. Nick told me he got a lot of feedback such as "Wow! I didn't know my brother-in-law is in my guild!" and "Its been 5 years since I talked to some of them, but a bunch of my friends from school play on these realms and I didn't even know they played".
Some facts:
- 53.5k installs
- 2.9k daily active users
- 1.3k application fans
- 200+ new users a day on average
- In the past 30 days its gotten over 2 million page views where users spend more than 5 minutes on average on the application
- Erlang application layout:
* Charstore w/ Mnesia: Acts as the raw character store and cache for interactions between wowarmory.com
* I Play WoW w/ ErlyWeb + Mnesia: The front-end and ui for the application. The majority of the FB API calls are made here or are spawned from here.
* There is still one component in perl that is yet to be ported over, mainly due to not having enough time. Its on the list of things to do.
(My note: it sounds like Nick is also using spawned processes to make FB API calls asynchronously. It's a great technique for reducing page load time and avoiding the annoying timeouts Facebook imposes on page renderings.)
If you play World of Warcraft (an addiction I've luckily been able to avoid this far :) ) and you are on Facebook, give I Play WoW a try. You may discover that your boss is a level 10 ogre or something :)
Congrats, Nick, for creating such a successful app with ErlyWeb!
Some facts:
- 53.5k installs
- 2.9k daily active users
- 1.3k application fans
- 200+ new users a day on average
- In the past 30 days its gotten over 2 million page views where users spend more than 5 minutes on average on the application
- Erlang application layout:
* Charstore w/ Mnesia: Acts as the raw character store and cache for interactions between wowarmory.com
* I Play WoW w/ ErlyWeb + Mnesia: The front-end and ui for the application. The majority of the FB API calls are made here or are spawned from here.
* There is still one component in perl that is yet to be ported over, mainly due to not having enough time. Its on the list of things to do.
(My note: it sounds like Nick is also using spawned processes to make FB API calls asynchronously. It's a great technique for reducing page load time and avoiding the annoying timeouts Facebook imposes on page renderings.)
If you play World of Warcraft (an addiction I've luckily been able to avoid this far :) ) and you are on Facebook, give I Play WoW a try. You may discover that your boss is a level 10 ogre or something :)
Congrats, Nick, for creating such a successful app with ErlyWeb!
Sunday, March 16, 2008
SnapTalent Ads
You may have noticed I put SnapTalent (http://snaptalent) ads on my blog. This is the first time I have put ads on my blog. I've avoided them because ads from most ad networks are usually irritating/ugly, but the SnapTalent ones are nice looking, unobtrusive and are relevant to my blog's readers because they advertise hacker jobs at startups. I can't say those ads have generated substantial revenue for me thus far but at least I've made enough money to buy the SnapTalent guys a round of beers :)
Sunday, March 09, 2008
In Response to "What Sucks About Erlang"
Damien Katz's latest blog post lists some ways in which Damien Katz thinks Erlang sucks. I agree with some of these points but not with all of them. Below are my responses to some of his complaints:
1. Basic Syntax
I've heard many people express their dislike for the Erlang syntax. I found the syntax a bit weird when I started using it, but once I got used to it it hasn't bothered me much. Sometimes I mess up and use the wrong expression terminator, and sometimes things break when I cut and paste code between function clauses, but it hasn't been real pain point for me. I understand where the complaints are coming from, but IMHO it's a minor issue.
Since the release of LFE last week, if you don't like the Erlang syntax, you can write Erlang code using Lisp Syntax, with full support for Lisp macros. If you prefer Lisp syntax to Erlang syntax, you have a choice.
2. 'if' expressions
The first issue is that in an 'if' expression, the condition has to match one of the clauses, or an exception is thrown. This means you can't write simple code like
and instead you have to write
This requirement may seem annoying, but it is there for a good reason. In Erlang, all expressions (except for 'exit()') must return a value. You should always be able to write
A = foo();
and expect A to be bound to a value. There is no "null" value in Erlang (the 'undefined' atom usually takes its place).
Fortunately, Erlang lets you get around this issue with a one-line macro:
Then you can use it as follows:
It's not that bad, is it?
This solution does have a shortcoming, though, which is that it only works for a single-clause 'if' expression. If it has multiple clauses, you're back where you started. That's where you should take a second look at LFE :)
The second issue about 'if' expressions is that you can't call any user- defined function in the conditional, just a subset of the Erlang BIFs. You can get around this limitation by using 'case', but again you have to provide a 'catch all' clause. For a single clause, you can simply change the macro I created to use a case statement.
For an arbitrary number of clauses, a macro won't help, and this is something you'll just have to live with. If it really bothers you, use LFE.
3. Strings
The perennial complaint against Erlang is that it "sucks" for strings. Erlang represents strings as lists of integers, and for some reason many people are convinced that this is tantamount to suckage.
A string *is* a list of integers -- why should we not represent it as such? If you care about the type of list you're dealing with, you should embed it in a tuple with a type description, e.g.
But if you don't care what the type is, representing a string as a list makes a lot of sense because it lets you leverage all the tools Erlang has for working with lists.
A real issue with using lists is that it's a memory-hungry data structure, especially on 64 bit machines, where you need 128 bits = 16 bytes to store each character. If your application processes such massive amounts of string data that this becomes a bottleneck, you can always use binaries. In fact, you should always use binaries for "static" strings on which you don't need to do character-level manipulation in code. ErlTL, for example, compiles all static template data as binaries to save memory.
I disagree with this statement, but instead of rebutting it directly, I'll suggest a new kind of Erlang challenge: build a webapp in Erlang and show me how string handling was a problem for you. I've heard a number of people say that Erlang's string handling is a hinderance in building webapps, but by my experience this simply isn't true. If you ran into real problems with strings when building a webapp, I would be very interested in hearing about them, but otherwise it's a waste of time hypothesizing about problems that don't exist.
4. Functional Programming Mismatch
The issue here is that Erlang's variable immutability supposedly makes writing test code difficult.
This is an issue that I ran into in a couple of places, and I agree that it can be annoying. However, discussing this consequence of immutability without mentioning its benefits is missing a big part of the picture. I really think that immutability is one of Erlang's best traits. Immutability makes code much more readable and easy to debug. For a trivial example, consider this Javascript code:
What does the function return? We have no idea. To answer this question, we have to read the code for baz() and recursively descend into all the functions that baz() calls with 'a' as a parameter. Even running the code doesn't help because it's possible that baz() only modifies 'a' based on some unpredictable event such as some user input.
Consider the Erlang version:
Because of variable immutability, we know that this function returns '1'.
I think that the guarantee that a variable's value will never change after it's bound is a great language feature and it far outweighs the disadvantage of having to use with unique variable names in functions that do a series of modifications to some data.
If you're writing code like in Damien's example and you want to be able to insert lines without changing a bunch of variable names, I have a tip: increment by 10. This will prevent the big cascading variable renamings in most situations. Instead of the original code, write
then change it as follows when inserting a new line in the middle:
Yes, I know, it's not exactly beautiful, but in the rare cases where you need it, it's a useful trick.
This issue could be rephrased as a complaint against imperative languages: "I don't know if the function to which I pass my variable will change it! It's too hard to track down all the places in the code where my data could get mangled!" This may sound outlandish especially if you haven't coded in Erlang or Haskell, but that's how I really feel sometimes when I go back from Erlang to an imperative language.
I don't understand this argument. Webapps need to be tested just like any other application. I don't see where the distinction lies.
5. Records
Many people hate records and on this topic I fully agree with Damien. I think the OTP team should just integrate Recless into the language and thereby solve most of the issues people have with records.
If you really hate records, another option is to use LFE, which automatically generates getters and setters for record properties.
Incidentally, if you use ErlyWeb with ErlyDB, you probably won't use records at all and you won't run into these annoyances. ErlyDB generates functions for accessing object properties which is much nicer than using the record syntax. ErlyDB also lets you access properties dynamically, which records don't allow, e.g.
Records are ugly, but if you're creating an ErlyWeb app, you probably won't need them. If they do cause you a great deal of pain, you can go ahead and help me finish Recless and then bug the OTP team to integrate it into the language :)
6. Code oragnization
I think this issue occurs in many programming languages, and I don't think Erlang is the biggest offender here. Unlike Java, for instance, Erlang doesn't restrict you to defining a single data type per module. And Ruby (especially Rails) applications are also known for having multitudes of small files. In Erlang, you indeed have to create a module per gen-server and the other 'behaviors' but depending on the application this may not be an issue. However, I don't think there's anything wrong with keeping different gen-servers in different modules. It should make the code more organized, not less.
7. Uneven Libraries and Documentation
I haven't had a problem with most libraries, and in cases where they do have big shortcomings you can often find a good 3rd party tool. The documentation is a pain to browse and search, but gotapi.com makes some of this pain go away.
Summary
Is Erlang perfect? Certainly not. But sometimes people exaggerate Erlang's problems or they don't address the full picture.
Here are some suggestions I have for improving Erlang:
- Add a Recless-like functionality to make working with records less painful.
- Improve the online documentation by making it easier to browse and search.
- Make some of the string APIs (especially the regexp library) also work with binaries and iolists.
- Add support for overloading macros, just like functions.
- Add support for Smerl-style function inheritance between modules.
Like any language, Erlang has some warts. But if it were perfect, it would be boring, wouldn't it? :)
1. Basic Syntax
I've heard many people express their dislike for the Erlang syntax. I found the syntax a bit weird when I started using it, but once I got used to it it hasn't bothered me much. Sometimes I mess up and use the wrong expression terminator, and sometimes things break when I cut and paste code between function clauses, but it hasn't been real pain point for me. I understand where the complaints are coming from, but IMHO it's a minor issue.
Since the release of LFE last week, if you don't like the Erlang syntax, you can write Erlang code using Lisp Syntax, with full support for Lisp macros. If you prefer Lisp syntax to Erlang syntax, you have a choice.
2. 'if' expressions
The first issue is that in an 'if' expression, the condition has to match one of the clauses, or an exception is thrown. This means you can't write simple code like
if Logging -> log("something") end
and instead you have to write
if Logging -> log("something"); true -> ok end
This requirement may seem annoying, but it is there for a good reason. In Erlang, all expressions (except for 'exit()') must return a value. You should always be able to write
A = foo();
and expect A to be bound to a value. There is no "null" value in Erlang (the 'undefined' atom usually takes its place).
Fortunately, Erlang lets you get around this issue with a one-line macro:
-define(my_if(Predicate, Expression), if Predicate -> Expression; true -> undefined end).
Then you can use it as follows:
?my_if(Logging, log("something"))
It's not that bad, is it?
This solution does have a shortcoming, though, which is that it only works for a single-clause 'if' expression. If it has multiple clauses, you're back where you started. That's where you should take a second look at LFE :)
The second issue about 'if' expressions is that you can't call any user- defined function in the conditional, just a subset of the Erlang BIFs. You can get around this limitation by using 'case', but again you have to provide a 'catch all' clause. For a single clause, you can simply change the macro I created to use a case statement.
-define(case(Predicate, Expression), case Predicate -> Expression; _ -> undefined end).
For an arbitrary number of clauses, a macro won't help, and this is something you'll just have to live with. If it really bothers you, use LFE.
3. Strings
The perennial complaint against Erlang is that it "sucks" for strings. Erlang represents strings as lists of integers, and for some reason many people are convinced that this is tantamount to suckage.
...you can't distinguish easily at runtime between a string and a list, and especially between a string and a list of integers.
A string *is* a list of integers -- why should we not represent it as such? If you care about the type of list you're dealing with, you should embed it in a tuple with a type description, e.g.
{string, "dog"},
{instruments, [guitar, bass, drums]}
But if you don't care what the type is, representing a string as a list makes a lot of sense because it lets you leverage all the tools Erlang has for working with lists.
A real issue with using lists is that it's a memory-hungry data structure, especially on 64 bit machines, where you need 128 bits = 16 bytes to store each character. If your application processes such massive amounts of string data that this becomes a bottleneck, you can always use binaries. In fact, you should always use binaries for "static" strings on which you don't need to do character-level manipulation in code. ErlTL, for example, compiles all static template data as binaries to save memory.
Erlang string operations are just not as simple or easy as most languages with integrated string types. I personally wouldn't pick Erlang for most front-end web application work. I'd probably choose PHP or Python, or some other scripting language with integrated string handling.
I disagree with this statement, but instead of rebutting it directly, I'll suggest a new kind of Erlang challenge: build a webapp in Erlang and show me how string handling was a problem for you. I've heard a number of people say that Erlang's string handling is a hinderance in building webapps, but by my experience this simply isn't true. If you ran into real problems with strings when building a webapp, I would be very interested in hearing about them, but otherwise it's a waste of time hypothesizing about problems that don't exist.
4. Functional Programming Mismatch
The issue here is that Erlang's variable immutability supposedly makes writing test code difficult.
Immutable variables in Erlang are hard to deal with when you have code that tends to change a lot, like user application code, where you are often performing a bunch of arbitrary steps that need to be changed as needs evolve.
In C, lets say you have some code:
int f(int x) {
x = foo(x);
x = bar(x);
return baz(x);
}
And you want to add a new step in the function:
int f(int x) {
x = foo(x);
x = fab(x);
x = bar(x);
return baz(x);
}
Only one line needs editing,
Consider the Erlang equivalent:
f(X) ->
X1 = foo(X),
X2 = bar(X1),
baz(X2).
Now you want to add a new step, which requires editing every variable thereafter:
f(X) ->
X1 = foo(X),
X2 = fab(X1),
X3 = bar(X2),
baz(X3).
This is an issue that I ran into in a couple of places, and I agree that it can be annoying. However, discussing this consequence of immutability without mentioning its benefits is missing a big part of the picture. I really think that immutability is one of Erlang's best traits. Immutability makes code much more readable and easy to debug. For a trivial example, consider this Javascript code:
function test() {
var a = {foo: 1; bar: 2};
baz(a);
return a.foo;
}
What does the function return? We have no idea. To answer this question, we have to read the code for baz() and recursively descend into all the functions that baz() calls with 'a' as a parameter. Even running the code doesn't help because it's possible that baz() only modifies 'a' based on some unpredictable event such as some user input.
Consider the Erlang version:
test() ->
A = [{foo, 1}, {bar, 2}],
baz(A),
proplists:get_value(A, foo).
Because of variable immutability, we know that this function returns '1'.
I think that the guarantee that a variable's value will never change after it's bound is a great language feature and it far outweighs the disadvantage of having to use with unique variable names in functions that do a series of modifications to some data.
If you're writing code like in Damien's example and you want to be able to insert lines without changing a bunch of variable names, I have a tip: increment by 10. This will prevent the big cascading variable renamings in most situations. Instead of the original code, write
f(X) ->
X10 = foo(X),
X20 = bar(X10),
baz(X20).
then change it as follows when inserting a new line in the middle:
f(X) ->
X10 = foo(X),
X15 = fab(X10),
X20 = bar(X15),
baz(X20).
Yes, I know, it's not exactly beautiful, but in the rare cases where you need it, it's a useful trick.
This issue could be rephrased as a complaint against imperative languages: "I don't know if the function to which I pass my variable will change it! It's too hard to track down all the places in the code where my data could get mangled!" This may sound outlandish especially if you haven't coded in Erlang or Haskell, but that's how I really feel sometimes when I go back from Erlang to an imperative language.
Erlang wasn't a good match for tests and for the same reasons I don't think it's a good match for front-end web applications.
I don't understand this argument. Webapps need to be tested just like any other application. I don't see where the distinction lies.
5. Records
Many people hate records and on this topic I fully agree with Damien. I think the OTP team should just integrate Recless into the language and thereby solve most of the issues people have with records.
If you really hate records, another option is to use LFE, which automatically generates getters and setters for record properties.
Incidentally, if you use ErlyWeb with ErlyDB, you probably won't use records at all and you won't run into these annoyances. ErlyDB generates functions for accessing object properties which is much nicer than using the record syntax. ErlyDB also lets you access properties dynamically, which records don't allow, e.g.
P = person:new_with([{name, "Paul"}]),
Fields = person:db_field_names(),
[io:format("~p: ~p~n", [Field, person:Field(P)]) || Field <- Fields]
Records are ugly, but if you're creating an ErlyWeb app, you probably won't need them. If they do cause you a great deal of pain, you can go ahead and help me finish Recless and then bug the OTP team to integrate it into the language :)
6. Code oragnization
Every time time you need to create something resembling a class (like an OTP generic process), you have to create whole Erlang file module, which means a whole new source file with a copyright banner plus the Erlang cruft at the top of each source file, and then it must be added to build system and source control. The extra file creation artificially spreads out the code over the file system, making things harder to follow.
I think this issue occurs in many programming languages, and I don't think Erlang is the biggest offender here. Unlike Java, for instance, Erlang doesn't restrict you to defining a single data type per module. And Ruby (especially Rails) applications are also known for having multitudes of small files. In Erlang, you indeed have to create a module per gen-server and the other 'behaviors' but depending on the application this may not be an issue. However, I don't think there's anything wrong with keeping different gen-servers in different modules. It should make the code more organized, not less.
7. Uneven Libraries and Documentation
I haven't had a problem with most libraries, and in cases where they do have big shortcomings you can often find a good 3rd party tool. The documentation is a pain to browse and search, but gotapi.com makes some of this pain go away.
Summary
Is Erlang perfect? Certainly not. But sometimes people exaggerate Erlang's problems or they don't address the full picture.
Here are some suggestions I have for improving Erlang:
- Add a Recless-like functionality to make working with records less painful.
- Improve the online documentation by making it easier to browse and search.
- Make some of the string APIs (especially the regexp library) also work with binaries and iolists.
- Add support for overloading macros, just like functions.
- Add support for Smerl-style function inheritance between modules.
Like any language, Erlang has some warts. But if it were perfect, it would be boring, wouldn't it? :)
Tuesday, March 04, 2008
Favorite Lisps Poll Result
With 78 responses so far, here are the breakdowns for the responders' favorite Lisps:
Scheme: 41%
Common Lisp: 27%
LFE: 12%
Arc: 10%
Emacs Lisp: 6%
Clojure: 4%
You can see the full report here.
I thought that Common Lisp would get more votes Scheme (isn't CL more widely used?), but apparently I was wrong. Arc and LFE have made an impressive showing for their young age (but this is probably due to the bias of my blog readers).
Scheme: 41%
Common Lisp: 27%
LFE: 12%
Arc: 10%
Emacs Lisp: 6%
Clojure: 4%
You can see the full report here.
I thought that Common Lisp would get more votes Scheme (isn't CL more widely used?), but apparently I was wrong. Arc and LFE have made an impressive showing for their young age (but this is probably due to the bias of my blog readers).
Monday, March 03, 2008
Introducing Presidential Vimagi, Where Anyone Can Paint Political Cartoons for US Presidents
With elections around the corner and politics everywhere these days, I couldn't resist throwing some Erlang into the mix. Don't worry, I'm not about to start discussing my political opinions on this blog. You can find plenty of political commentary on other sites. Instead, I decided to create a sub-Vimagi for political cartoons: Presidential Vimagi.
On Presidential Vimagi, you don't write or talk about your political views. You paint them. If a picture is worth a thousand words, a painting is worth, well, you do the math.
To give you inspiration, I assembled an all star cast of American presidents, vice presidents and presidential candidates: George Bush, Dick Cheney, Barak Obama, Hillary Clinton, Mike Huckabee, John McCain, Ron Paul, Bill Clinton and Al Gore. They each have a profile and you can paint on their profile's v.boards. You can also become friends with them if you want to show your support.
Presidential Vimagi is still a bit rough around the edges, so please let me know if you find any bugs or issues. Feature suggestions are also welcome, of course.
Update: I decided to take the site down for now. It's too prone to vandalism and I don't have the time to constantly monitor it to remove the offensive stuff. It was a fun experiment while it lasted. Oh well :)
On Presidential Vimagi, you don't write or talk about your political views. You paint them. If a picture is worth a thousand words, a painting is worth, well, you do the math.
To give you inspiration, I assembled an all star cast of American presidents, vice presidents and presidential candidates: George Bush, Dick Cheney, Barak Obama, Hillary Clinton, Mike Huckabee, John McCain, Ron Paul, Bill Clinton and Al Gore. They each have a profile and you can paint on their profile's v.boards. You can also become friends with them if you want to show your support.
Presidential Vimagi is still a bit rough around the edges, so please let me know if you find any bugs or issues. Feature suggestions are also welcome, of course.
Update: I decided to take the site down for now. It's too prone to vandalism and I don't have the time to constantly monitor it to remove the offensive stuff. It was a fun experiment while it lasted. Oh well :)
Saturday, March 01, 2008
Lisp Flavored Erlang!
Erlang has a Lisp syntax! Robert Virding just released LFE, his Lisp syntax compiler for Erlang. Finally, Erlang hackers enjoy the full power Lisp-style macros. I suspect it won't be long before you'll be able to hack ErlyWeb apps in LFE :)
While you're here, please answer this Wufoo poll:
Powered by Wufoo
While you're here, please answer this Wufoo poll:
Powered by Wufoo
Wednesday, February 27, 2008
Your Daily Dose of Erlang Evangelism
This is a good one I fished from the mailing list:
http://www.nabble.com/Steve-Vinosky-interview-to15709698.html#a15720750
Using Erlang continually makes me both smile and cry at the same time. I smile because of the overall simplicity it brings to solving all those hard issues I mentioned above, but I also cry knowing how many hours, days, weeks, and months my former colleagues and I spent trying
to solve all those really hard issues.
http://www.nabble.com/Steve-Vinosky-interview-to15709698.html#a15720750
Sunday, February 17, 2008
Seaside-Style Programming in ErlyWeb
The Arc Challenge started an interesting thread in the ErlyWeb mailing list about continuations-driven web frameworks. ErlyWeb doesn't have built-in support for continuations, but Arc does and so does Seaside. I haven't paid much attention to the use of continuations in web frameworks before the Arc challenge, but I became especially interested in experimenting with them after seeing Seaside solution.
In case you haven't read it, this is the requirement of the Arc challenge:
This is the original Arc solution:
This is how you would write the same logic in Erlang, if it had an Arc-like web framework:
The Erlang code is a bit more verbose, mostly because Erlang macros don't allow you to hide the "fun() -> ... end" syntax the way Lisp macros let you hide the (lambda ..) keyword.
This is the Seaside solution:
IMO, this solution cheats a bit by using high-level functions for generating the HTML tags whereas the Arc version generates them explicitly. However, putting minor complaints aside, I think the Seaside version is the winner in readability. As a reddit comment said, it reads like prose. It doesn't even declare any closures explicitly -- it says exactly what it does and nothing more.
Wouldn't it be cool if we could use this style of programming in ErlyWeb applications?
Fortunately, we can! I hacked a continuations plugin for ErlyWeb that lets you write Seaside-style code so fans of this programming style would feel at home with ErlyWeb. (This is all done in 105 lines of code :) ) Before I explain how the plugin works, I'll show you how to create an ErlyWeb controller that implements the the Arc challenge using this plugin:
This may seem more verbose than the Seaside code because of the module declarations at the top, but the "meat" is about the same. (I could make this code even smaller by integrating continations.erl deep into ErlyWeb, which would remove the explicit call to continuations:do(). However, I didn't want to go too far with this proof of concept.)
How does this work? Using concurrency, of course! For each "continuation", the plugin spawns a process and registers it in a Mnesia table according to a randomly generated key. The key (K) is encoded in the URLs to which the <form> and <a> tags point. When a request arrives, continuations:do() looks up the process in Mnesia and sends it a message of the type {A, self()}. The process does some work and sends back in reply the HTML to be rendered, and waits for the next message. The web server process receives the rendered HTML and sends it to the client using the normal ErlyWeb mechanisms.
If a process doesn't receive a message in 10 seconds, it dies and removes itself from the Mnesia table, which provides automatic garbage collection to stale sessions.
You can get the code for continuations.erl here. Just remember it's a proof of concept and I don't recommend using it in a production environment.
(Before you use it in your application, make sure you call continuations:start().)
Final word: IMO, although continuations help write more natural code in certain multi-page interactions, most of the logic in web applications involves rendering dynamic pages for RESTful URLs. So, if your web framework doesn't support continuations, don't worry about it too much. It's likely the code for your application wouldn't be dramatically smaller if you could write it with the use of continuations. (That said, take my advice with a grain of salt. I haven't used a continuations based framework to build a real application, so I may be missing something.)
In case you haven't read it, this is the requirement of the Arc challenge:
Write a program that causes the url said (e.g. http://localhost:port/said) to produce a page with an input field and a submit button. When the submit button is pressed, that should produce a second page with a single link saying "click here." When that is clicked it should lead to a third page that says "you said: ..." where ... is whatever the user typed in the original input field. The third page must only show what the user actually typed. I.e. the value entered in the input field must not be passed in the url, or it would be possible to change the behavior of the final page by editing the url.
This is the original Arc solution:
(defop said req
(aform [w/link (pr "you said: " (arg _ "foo"))
(pr "click here")]
(input "foo")
(submit)))
This is how you would write the same logic in Erlang, if it had an Arc-like web framework:
said(A) ->
form(
fun(A1) ->
link(fun(A2) -> ["you said ", get_var(A1, "foo")] end,
"click here")
end,
[input("foo"),
submit()]).
The Erlang code is a bit more verbose, mostly because Erlang macros don't allow you to hide the "fun() -> ... end" syntax the way Lisp macros let you hide the (lambda ..) keyword.
This is the Seaside solution:
| something |
something := self request: 'Say something'.
self inform: 'Click here'.
self inform: something
IMO, this solution cheats a bit by using high-level functions for generating the HTML tags whereas the Arc version generates them explicitly. However, putting minor complaints aside, I think the Seaside version is the winner in readability. As a reddit comment said, it reads like prose. It doesn't even declare any closures explicitly -- it says exactly what it does and nothing more.
Wouldn't it be cool if we could use this style of programming in ErlyWeb applications?
Fortunately, we can! I hacked a continuations plugin for ErlyWeb that lets you write Seaside-style code so fans of this programming style would feel at home with ErlyWeb. (This is all done in 105 lines of code :) ) Before I explain how the plugin works, I'll show you how to create an ErlyWeb controller that implements the the Arc challenge using this plugin:
-module(said_controller).
-compile(export_all).
-import(continuations, [ask/2, confirm/2, pr/1]).
index(A) ->
continuations:do(
A, fun(K) ->
Name = ask(K, "name"),
confirm(K, "click here"),
pr(["your name: ", Name])
end).
This may seem more verbose than the Seaside code because of the module declarations at the top, but the "meat" is about the same. (I could make this code even smaller by integrating continations.erl deep into ErlyWeb, which would remove the explicit call to continuations:do(). However, I didn't want to go too far with this proof of concept.)
How does this work? Using concurrency, of course! For each "continuation", the plugin spawns a process and registers it in a Mnesia table according to a randomly generated key. The key (K) is encoded in the URLs to which the <form> and <a> tags point. When a request arrives, continuations:do() looks up the process in Mnesia and sends it a message of the type {A, self()}. The process does some work and sends back in reply the HTML to be rendered, and waits for the next message. The web server process receives the rendered HTML and sends it to the client using the normal ErlyWeb mechanisms.
If a process doesn't receive a message in 10 seconds, it dies and removes itself from the Mnesia table, which provides automatic garbage collection to stale sessions.
You can get the code for continuations.erl here. Just remember it's a proof of concept and I don't recommend using it in a production environment.
(Before you use it in your application, make sure you call continuations:start().)
Final word: IMO, although continuations help write more natural code in certain multi-page interactions, most of the logic in web applications involves rendering dynamic pages for RESTful URLs. So, if your web framework doesn't support continuations, don't worry about it too much. It's likely the code for your application wouldn't be dramatically smaller if you could write it with the use of continuations. (That said, take my advice with a grain of salt. I haven't used a continuations based framework to build a real application, so I may be missing something.)
Sunday, February 10, 2008
More Erlang Fun: Distributed, Fault Tolerant MapReduce
I the Erlang Challenge posting, I showed how to implement a simple distributed parallel map function. You can pass it a list of nodes, and it performs each application of F1 on a random node ("node" means a connected Erlang VM that may exist on a different machine) from the list. Finally, it collects the results in the order of the arguments.
What Erlang nailed beside concurrent and distributed programming is fault tolerance. When processes die or nodes go down, the VM notifies their supervisors so they can perform error recovery. My previous example didn't demonstrate this capability, so in this article I'll show how to implement a similar solution but also taking into account node failures. In addition, instead of doing just a simple parallel map, this example will also fold the results, making it a basic MapReduce implementation.
(The reason I'm adding the 'reduce' phase is because it allows me to not worry about the order at which the results are accumulated. This implies that the reduce operation must be commutative.)
The function mapreduce() takes a function F1 and applies to elements of list L. Each application is performed on a remote node from Nodes. As opposed to the pmap() example, this implementation chooses the next node from the list in a rotating fashion instead of randomly (i.e., if Nodes is [A, B, C], then F1 is applied on remote nodes with the following order: A, B, C, A, B, C, A ...). The results are collected, and if any nodes went down, their computations are retried on the remaining nodes until all computations succeed or no nodes are left. If the computations all succeed, we call lists:foldl(F2, Acc, Vals), where Vals contains the results of the computations.
Implementation details:
- do_map() returns a list of {Pid, X} tuples. Pid is the process on the remote node in which F1 was applied to X. The reason we want to remember X is that if Pid's node goes down, we can later retry to evaluate F1(X) on a different node.
- For each {Pid, X} tuple, collect() receives either an {ok, Pid, Val} message, indicating the computation was performed successfully, or {nodedown, Node}, indicating the node on which Pid lived went down. collect() folds the result into a tuple of type {Successes, Failures, RemainingNodes}. If Failures is not empty, collect() calls do_map() on the list of Failures and the remaining nodes, and then recursively calls itself on the result and appends the outcome to Successes.
The code is below. (Note that I didn't test it, so it may have bugs :) )
This is more complex than the pmap() example, but I think it packs a lot of functionality into a relatively small amount of code
What Erlang nailed beside concurrent and distributed programming is fault tolerance. When processes die or nodes go down, the VM notifies their supervisors so they can perform error recovery. My previous example didn't demonstrate this capability, so in this article I'll show how to implement a similar solution but also taking into account node failures. In addition, instead of doing just a simple parallel map, this example will also fold the results, making it a basic MapReduce implementation.
(The reason I'm adding the 'reduce' phase is because it allows me to not worry about the order at which the results are accumulated. This implies that the reduce operation must be commutative.)
The function mapreduce() takes a function F1 and applies to elements of list L. Each application is performed on a remote node from Nodes. As opposed to the pmap() example, this implementation chooses the next node from the list in a rotating fashion instead of randomly (i.e., if Nodes is [A, B, C], then F1 is applied on remote nodes with the following order: A, B, C, A, B, C, A ...). The results are collected, and if any nodes went down, their computations are retried on the remaining nodes until all computations succeed or no nodes are left. If the computations all succeed, we call lists:foldl(F2, Acc, Vals), where Vals contains the results of the computations.
Implementation details:
- do_map() returns a list of {Pid, X} tuples. Pid is the process on the remote node in which F1 was applied to X. The reason we want to remember X is that if Pid's node goes down, we can later retry to evaluate F1(X) on a different node.
- For each {Pid, X} tuple, collect() receives either an {ok, Pid, Val} message, indicating the computation was performed successfully, or {nodedown, Node}, indicating the node on which Pid lived went down. collect() folds the result into a tuple of type {Successes, Failures, RemainingNodes}. If Failures is not empty, collect() calls do_map() on the list of Failures and the remaining nodes, and then recursively calls itself on the result and appends the outcome to Successes.
The code is below. (Note that I didn't test it, so it may have bugs :) )
-module(mapreduce).
-export([mapreduce/5]).
mapreduce(F1, F2, Acc, L, Nodes) ->
%% map F1 to the elements of L on nodes from Nodes
Results = do_map(F1, L, Nodes),
%% collect the results, retrying in the event of failures
Vals = collect(F1, Results, Nodes),
%% perform the reduce operation
lists:foldl(F2, Acc, Vals).
%% exit if we ran out of good nodes
do_map(_F1, _L, []) -> exit(no_nodes);
do_map(F1, L, Nodes) ->
Parent = self(),
%% apply F1 to values of L on remote nodes in a rotating fashion
{Results, _Nodes1} =
lists:foldl(
fun(X, {Acc, [Node | Rest]}) ->
erlang:monitor_node(Node),
Fun = fun() -> Parent ! {ok, self(), (catch F1(X))} end,
Pid = spawn(Node, Fun),
{[{Pid, X} | Acc], Rest ++ [Node]}
end, {[], Nodes}, L),
Results.
collect(F1, Results, Nodes) ->
collect(F1, Results, Nodes, []).
collect(F1, Results, Nodes, Acc) ->
{Successes, Failures, RemainingNodes}=
lists:foldl(
fun({Pid, X}, {Successes1, Failures1, Nodes1}) ->
Node = node(Pid),
receive
{ok, Pid, Val} ->
{[Val | Successes1], Failures1, Nodes1};
%% we may receive this message because of call to
%% monitor_node()
{nodedown, Node} ->
{Successes1, [X | Failures1], Nodes1 -- Node}
end
end, {[], [], Nodes}, Results),
if Failures =/= [] ->
%% retry the failed computations on the remaining nodes
%% and add the results to the current list of successes
Results2 = do_map(F1, Failures, RemainingNodes),
collect(F1, Results2, RemainingNodes, Successes ++ Acc);
true ->
Successes ++ Acc
end.
This is more complex than the pmap() example, but I think it packs a lot of functionality into a relatively small amount of code
Friday, February 08, 2008
Erlang Challenge Followup
After I published the Erlang Challenge, I saw a few comments on Hacker News and Reddit repudiating it with the following arguments, to which I'd like to respond:
- It was a snide response to the Arc challenge.
Maybe I should have read the article a couple of times over before I published it late last night, because if it came off as snide, I didn't communicate it as I had intended. I've found the Arc challenge fun and interesting (I even submitted my own Erlang solution), and I wouldn't intentionally respond to it in a snide way. The reason I said the Erlang challenge is in the spirit of the Arc challenge is that the Arc challenge highlights Arc's strengths, whereas the Erlang challenge highlights Erlang's strengths.
- It was rigged in favor of Erlang.
That was basically the point. I wanted the Erlang challenge to demonstrate the kinds of problems that Erlang excels at solving. Maybe I should have made this clearer when I wrote the article -- it was more of an illustration of Erlang's strengths than a "real" challenge. I wasn't really expecting other languages to compete with Erlang on its home turf, the same way I wouldn't expect Erlang to compete with, say, C or C++ at low-level systems programming or with ActionScript at Flash programming.
- It showed that Erlang is good at solving a narrow scope of problems, but I didn't show that Erlang is a good general purpose tool.
I don't think it's possible to show in 10 lines of code how good (or bad) a language is at solving anything but problems that are very similar to those in the example. The only true way to judge whether a language is good at building certain types of systems is to build them using the language and evaluate the results.
I know that people have used Erlang successfully to build phone switches, a MMORPG, a massively scalable DBMS, web applications, a collaboration application, high performance messaging servers, ad servers, web servers, a scalable poker server, and a 3D modeling tool. When I say that Erlang is a good language for building certain applications, that's what I base it on.
Edit: I forgot to list CouchDB, an open source document storage system, and Triggit, a widget server unlike any other.
- It was a snide response to the Arc challenge.
Maybe I should have read the article a couple of times over before I published it late last night, because if it came off as snide, I didn't communicate it as I had intended. I've found the Arc challenge fun and interesting (I even submitted my own Erlang solution), and I wouldn't intentionally respond to it in a snide way. The reason I said the Erlang challenge is in the spirit of the Arc challenge is that the Arc challenge highlights Arc's strengths, whereas the Erlang challenge highlights Erlang's strengths.
- It was rigged in favor of Erlang.
That was basically the point. I wanted the Erlang challenge to demonstrate the kinds of problems that Erlang excels at solving. Maybe I should have made this clearer when I wrote the article -- it was more of an illustration of Erlang's strengths than a "real" challenge. I wasn't really expecting other languages to compete with Erlang on its home turf, the same way I wouldn't expect Erlang to compete with, say, C or C++ at low-level systems programming or with ActionScript at Flash programming.
- It showed that Erlang is good at solving a narrow scope of problems, but I didn't show that Erlang is a good general purpose tool.
I don't think it's possible to show in 10 lines of code how good (or bad) a language is at solving anything but problems that are very similar to those in the example. The only true way to judge whether a language is good at building certain types of systems is to build them using the language and evaluate the results.
I know that people have used Erlang successfully to build phone switches, a MMORPG, a massively scalable DBMS, web applications, a collaboration application, high performance messaging servers, ad servers, web servers, a scalable poker server, and a 3D modeling tool. When I say that Erlang is a good language for building certain applications, that's what I base it on.
Edit: I forgot to list CouchDB, an open source document storage system, and Triggit, a widget server unlike any other.
Thursday, February 07, 2008
The Erlang Challenge
In the spirit of Paul Graham's Arc challenge, and in spite of the "controversy" around it, I devised a programming challenge of my own. It's called the Erlang Challenge.
The goal is to implement an advanced "parallel map": a function (F1) that applies another function (F2) to every element (E) of a list (L1) concurrently and then gathers the results in a new list (L2). The order of results in L2 corresponds to the order of elements in L1, and the elements of L1 are guaranteed to remain unchanged no matter what function F2 does. To make things more interesting, the F1 should also accept a list of cluster nodes (NL) onto which the computations can be distributed. Each application of F2 to an element of L1 should be done on a random node from NL, and the result should be send back to the node on which F1 was called (N). If NL is empty, all computations should occur locally on N.
This challenge isn't just about succinctness, but, like most real-world systems, also about scalability and performance. Therefore, it has the following requirements:
- The implementation must be able to spawn at least 1 million concurrent processes on a modern server machine.
- On multi-core machines, the application's performance must increase (almost) linearly with the number of available CPUs.
- The application as a whole must exhibit soft real-time performance. Specifically, this means that processes won't freeze for a long time during global garbage collection sweeps, and that no process will be able to block the entire VM to do IO or call native code, regardless of what F2 does. In other words, it is impossible to create a function F2 that could block the scheduler while F2 executes.
Here's how I would implement it in Erlang (this is loosely based on Joe Armstrong's pmap implementation):
How would you implement it in your favorite language?
Update: please read the followup.
The goal is to implement an advanced "parallel map": a function (F1) that applies another function (F2) to every element (E) of a list (L1) concurrently and then gathers the results in a new list (L2). The order of results in L2 corresponds to the order of elements in L1, and the elements of L1 are guaranteed to remain unchanged no matter what function F2 does. To make things more interesting, the F1 should also accept a list of cluster nodes (NL) onto which the computations can be distributed. Each application of F2 to an element of L1 should be done on a random node from NL, and the result should be send back to the node on which F1 was called (N). If NL is empty, all computations should occur locally on N.
This challenge isn't just about succinctness, but, like most real-world systems, also about scalability and performance. Therefore, it has the following requirements:
- The implementation must be able to spawn at least 1 million concurrent processes on a modern server machine.
- On multi-core machines, the application's performance must increase (almost) linearly with the number of available CPUs.
- The application as a whole must exhibit soft real-time performance. Specifically, this means that processes won't freeze for a long time during global garbage collection sweeps, and that no process will be able to block the entire VM to do IO or call native code, regardless of what F2 does. In other words, it is impossible to create a function F2 that could block the scheduler while F2 executes.
Here's how I would implement it in Erlang (this is loosely based on Joe Armstrong's pmap implementation):
pmap(Fun, List, Nodes) ->
SpawnFun =
case length(Nodes) of
0 -> fun spawn/1;
Length ->
NextNode = fun() -> nth(random:uniform(Length), Nodes) end,
fun(F) -> spawn(NextNode(), F) end
end,
Parent = self(),
Pids = [SpawnFun(fun() -> Parent ! {self(), (catch Fun(Elem))} end)
|| Elem <- List],
[receive {Pid, Val} -> Val end || Pid <- Pids].
How would you implement it in your favorite language?
Update: please read the followup.
Monday, January 28, 2008
Debugging with Distel
Until recently, I've done my Erlang debugging either using the built-in debugger or not using a debugger at all and instead relying on the good old io:format() function. The reason I haven't been keen on using the Erlang debugger is that it's not integrated into my editor (I use Emacs). To debug a file, I'd have to open it separately in the debugger UI, where I could set breakpoints and step through the code. For simple bugs, this is more effort than adding a few io:format() statements, reloading the page, and figuring out the bug from the output.
I'm not an IDE fanatic (well, duh, I use Emacs) -- I can do fine without most of the features in advanced IDEs -- but I do expect any decent editor to have at least 3 features: syntax highlighting, auto-indentation, and integrated debugging.
(I'm ambivalent about IDEs with code completion. It adds convenience, but it also it lets you get by without really remembering your APIs. Without code completion, I remember most of the my application's function names and their parameters simply because not remembering them slows me down too much. This is akin to the cellphone effect on remembering numbers: before I had a cellphone, I remembered all my close friends and family members' numbers. Looking them up in an address book was too much work. Now, I remember just a fraction of them. My cellphone made me lazy.)
The Emacs mode for Erlang provides syntax highlighting and auto-indentation, but no integrated debugging. AFAIK, neither Erlide nor ErlyBird have integrated debuggers. I knew Distel was supposed to add debugging support, and I even tried setting it up a while ago but gave up after running into problems I couldn't figure out. Last weekend, though, I finally got it working after following Bill Clemenson's Distel tutorial. I must say that having a debugger integrated into Emacs is a huge improvement. I recommend it to every Erlang hacker.
My only peeve with this debugger is that you must mark each file you want to debug as interpreted (the Emacs shortcut is "C-c C-d i") before you can set breakpoints in it and step into its functions. This seems unnecessary -- Erlang .beam files usually contain metadata including the location of their source files. I wish the debugger used this information to auto-interpret all the files you're trying to debug.
This is a relatively small peeve, though. The Distel debugger is definitely a step up from io:format().
I'm still hoping someone will create a more user-friendly Erlang IDE with a slick UI and an integrated debugger. I like the TextMate interface, but TextMate doesn't do auto-indentation for Erlang or debugging. I'll stick to Emacs+Distel for now.
I'm not an IDE fanatic (well, duh, I use Emacs) -- I can do fine without most of the features in advanced IDEs -- but I do expect any decent editor to have at least 3 features: syntax highlighting, auto-indentation, and integrated debugging.
(I'm ambivalent about IDEs with code completion. It adds convenience, but it also it lets you get by without really remembering your APIs. Without code completion, I remember most of the my application's function names and their parameters simply because not remembering them slows me down too much. This is akin to the cellphone effect on remembering numbers: before I had a cellphone, I remembered all my close friends and family members' numbers. Looking them up in an address book was too much work. Now, I remember just a fraction of them. My cellphone made me lazy.)
The Emacs mode for Erlang provides syntax highlighting and auto-indentation, but no integrated debugging. AFAIK, neither Erlide nor ErlyBird have integrated debuggers. I knew Distel was supposed to add debugging support, and I even tried setting it up a while ago but gave up after running into problems I couldn't figure out. Last weekend, though, I finally got it working after following Bill Clemenson's Distel tutorial. I must say that having a debugger integrated into Emacs is a huge improvement. I recommend it to every Erlang hacker.
My only peeve with this debugger is that you must mark each file you want to debug as interpreted (the Emacs shortcut is "C-c C-d i") before you can set breakpoints in it and step into its functions. This seems unnecessary -- Erlang .beam files usually contain metadata including the location of their source files. I wish the debugger used this information to auto-interpret all the files you're trying to debug.
This is a relatively small peeve, though. The Distel debugger is definitely a step up from io:format().
I'm still hoping someone will create a more user-friendly Erlang IDE with a slick UI and an integrated debugger. I like the TextMate interface, but TextMate doesn't do auto-indentation for Erlang or debugging. I'll stick to Emacs+Distel for now.
Wednesday, January 23, 2008
Triggit: Why Didn't I think of That?
Triggit received some great publicity last week. Triggit, a small startup in San Francisco, recently released a product makes it easy to add widgets and ads to any site by dragging and dropping -- no HTML editing required. I think it can really catch on among bloggers who are disinclined to muck around in mounds of PHP code in order to add some widgets to their blogs. I can also see this kind of technology fitting very well in sites like MySpace, where non tech-savvy users could use Triggit to effortlessly soup up their profiles.
Ryan Tecco, Triggit's CTO, told me Triggit uses Erlang for all the heavy lifting in the backend. You probably won't find this shocking, but I think using Erlang is a smart choice. Low latency, scalability and high availability are all essential for this kind of product: it's one thing to have performance/availability issues on *your* site, but it's much worse to let those issues affect other people's sites as well.
Finally, Triggit is an interesting data point on how very small teams can successfully use Erlang to achieve impressive results in a short time frame.
Update: I added this video with Triggit :)
Ryan Tecco, Triggit's CTO, told me Triggit uses Erlang for all the heavy lifting in the backend. You probably won't find this shocking, but I think using Erlang is a smart choice. Low latency, scalability and high availability are all essential for this kind of product: it's one thing to have performance/availability issues on *your* site, but it's much worse to let those issues affect other people's sites as well.
Finally, Triggit is an interesting data point on how very small teams can successfully use Erlang to achieve impressive results in a short time frame.
Update: I added this video with Triggit :)
Monday, January 21, 2008
How to Use Concurrency to Improve Response Time in ErlyWeb Facebook Apps
When I was building the Vimagi Facebook app, I came across a common scenario where using concurrency can make your application more responsive for its users.
The typical flow of responding to requests coming from Facebook looks like this:
1) request arrives
2) do some stuff (mostly DB CRUD operations)
3) call Facebook API to send notifications / update newsfeeds and profile FBML
4) send response
When you're building a facebook app with ErlyWeb, you can instead do the following:
1) request arrives
2) do some stuff (mostly DB CRUD operations)
spawn(fun() ->
3) call Facebook API to send notifications / update newsfeeds and profile FBML
end)
4) send response
The Facebook API calls in step 3 are much more expensive than the typical ErlyWeb controller operations because these calls involve synchronous round trips to the Facebook servers plus XML processing for the responses. By performing the Facebook API calls in a new process we can return the rendered response to the browser immediately and let the Erlang VM schedule the Facebook API calls to happen leisurely in the background.
The only gotcha is that if an error occurs in the spawned process we can't notify the user right away -- but this isn't really problem because we can log the errors and retry later, which is arguably a better approach anyway from a usability standpoint.
It's really that easy! A simple call to spawn() makes our app *feel* much faster. This puts the debate around language performance comparisons in a new light: how do you take into account the observation that some languages make "cheating" so much easier? :)
The typical flow of responding to requests coming from Facebook looks like this:
1) request arrives
2) do some stuff (mostly DB CRUD operations)
3) call Facebook API to send notifications / update newsfeeds and profile FBML
4) send response
When you're building a facebook app with ErlyWeb, you can instead do the following:
1) request arrives
2) do some stuff (mostly DB CRUD operations)
spawn(fun() ->
3) call Facebook API to send notifications / update newsfeeds and profile FBML
end)
4) send response
The Facebook API calls in step 3 are much more expensive than the typical ErlyWeb controller operations because these calls involve synchronous round trips to the Facebook servers plus XML processing for the responses. By performing the Facebook API calls in a new process we can return the rendered response to the browser immediately and let the Erlang VM schedule the Facebook API calls to happen leisurely in the background.
The only gotcha is that if an error occurs in the spawned process we can't notify the user right away -- but this isn't really problem because we can log the errors and retry later, which is arguably a better approach anyway from a usability standpoint.
It's really that easy! A simple call to spawn() makes our app *feel* much faster. This puts the debate around language performance comparisons in a new light: how do you take into account the observation that some languages make "cheating" so much easier? :)
Sunday, January 20, 2008
Vimagi: The Facebook App
I finally finished the Vimagi Facebook app! Check out the screen shots:

The app works similar to the vimagi.com website: you can create paintings with titles, tags, and descriptions and share them with anyone. Other Facebook users can comment on the paintings and rate them. Paintings created in Facebook are automatically posted to vimagi.com, where vimagi.com users can also add comments and ratings. All paintings have embed codes you can use to embed them on any site (with playback). In Facebook, you can create paintings for your Facebook friends and those paintings will appear on their (and your) profile. Similar to vimagi.com, the Facebook app has a gallery and a tags page, which contains content from both vimagi.com and the Facebook app.
I created the Facebook app mostly as a learning exercise, but I also believe that the Vimagi features would appeal to more people by being embedded into people's their existing social network rather than in a standalone site.
Unfortunately, I underestimated how tricky it would be to port the vimagi.com features and code into Facebook without breaking the site and while seamlessly blending the paintings and data created on Facebook and on vimagi.com. (One of the pesky issues I encountered is that Facebook applications have root URLs of the form http://apps.facebook.com/[app name], which was incompatible with the vimagi.com relative URLs. The existing URLs all start with a forward slash, assuming they follow immediately after the domain name. My life would have been much better if Facebook used the url scheme "http://[app name].apps.facebook.com/" for Facebook apps as it would have allowed existing URLs to remain unmodified.)
If you like to paint, I hope you enjoy the applications, and if you have friends who like to paint, please send them an invitation. Facebook needs some more Erlang-generated pageviews :)
If you like Vimagi and you're on Facebook, please join the Vimagi fan club. Also, I'll appreciate it if you let me know of any feedback or suggestions you may have.
P.S. Thanks I to Bryan Fink for the excellent erlang2facebook library.
The app works similar to the vimagi.com website: you can create paintings with titles, tags, and descriptions and share them with anyone. Other Facebook users can comment on the paintings and rate them. Paintings created in Facebook are automatically posted to vimagi.com, where vimagi.com users can also add comments and ratings. All paintings have embed codes you can use to embed them on any site (with playback). In Facebook, you can create paintings for your Facebook friends and those paintings will appear on their (and your) profile. Similar to vimagi.com, the Facebook app has a gallery and a tags page, which contains content from both vimagi.com and the Facebook app.
I created the Facebook app mostly as a learning exercise, but I also believe that the Vimagi features would appeal to more people by being embedded into people's their existing social network rather than in a standalone site.
Unfortunately, I underestimated how tricky it would be to port the vimagi.com features and code into Facebook without breaking the site and while seamlessly blending the paintings and data created on Facebook and on vimagi.com. (One of the pesky issues I encountered is that Facebook applications have root URLs of the form http://apps.facebook.com/[app name], which was incompatible with the vimagi.com relative URLs. The existing URLs all start with a forward slash, assuming they follow immediately after the domain name. My life would have been much better if Facebook used the url scheme "http://[app name].apps.facebook.com/" for Facebook apps as it would have allowed existing URLs to remain unmodified.)
If you like to paint, I hope you enjoy the applications, and if you have friends who like to paint, please send them an invitation. Facebook needs some more Erlang-generated pageviews :)
If you like Vimagi and you're on Facebook, please join the Vimagi fan club. Also, I'll appreciate it if you let me know of any feedback or suggestions you may have.
P.S. Thanks I to Bryan Fink for the excellent erlang2facebook library.
Thursday, January 17, 2008
Join the ErlyWeb Fan Club on Facebook
Are you on Facebook? Then join the ErlyWeb Fan Club!
If all goes according to plan, some day this fan club will have more members than the If this group reaches 4,294,967,296 it might cause an integer overflow group :)
If all goes according to plan, some day this fan club will have more members than the If this group reaches 4,294,967,296 it might cause an integer overflow group :)
Subscribe to:
Posts (Atom)