Here's a good brain teaser to give you some entertainment for the new year.
You have 12 balls, identical in every way except that one of them has a different weight from all the others. You also have a balance scale. In 3 rounds, in each of which you can compare the weights of any 2 groups of balls, you have to ascertain which is the ball with the different weight and whether this ball is heavier or lighter than the other balls.
This is not a trick question in any way. I solved part of this puzzle after I got a significant hint. I wish I had tried a bit harder to solve it by myself, but it's too late now. If you want a hint, you can email me, but you'll feel greater satisfaction if you solve it by yourself.
Happy new year!
Saturday, December 30, 2006
Tuesday, December 19, 2006
ErlyWeb is Undocumented No More!
I resisted the distractions. Even the killer duo of Lord of the Rings books and the World Wide Web couldn't stop me (although it did slow me down considerably :) ). I finally managed to sit down on my ass until I finished writing the first draft of the ErlyWeb API documentation, in meticulous conformance to the edoc specification!
Yes, my friends, it's true. You can now go to http://erlyweb.org/ and feast your eyes on the most glorious API documentation ever written! Well, ok, I admit that may be a slight exaggeration, but it sure beats having to rely on a bunch of tutorials and source code, doesn't it? :)
If you find any glaring holes or errors, please let me know.
(To generate the HTML yourself, check out the latest version from trunk and do the equivalent of "edoc:application('ErlyWeb', "/path/to/erlyweb/trunk", [no_packages])", and the files will appear in erlyweb/doc.)
Enjoy!
Yes, my friends, it's true. You can now go to http://erlyweb.org/ and feast your eyes on the most glorious API documentation ever written! Well, ok, I admit that may be a slight exaggeration, but it sure beats having to rely on a bunch of tutorials and source code, doesn't it? :)
If you find any glaring holes or errors, please let me know.
(To generate the HTML yourself, check out the latest version from trunk and do the equivalent of "edoc:application('ErlyWeb', "/path/to/erlyweb/trunk", [no_packages])", and the files will appear in erlyweb/doc.)
Enjoy!
Tuesday, December 12, 2006
ErlyWeb Tutorial by Brian Olsen, Part 2
Brian Olsen wrote the second part of his ErlyWeb tutorial. In this part, he shows how to acheive maximum code reuse for editing and creating new postings by making smart use of higher-order functions. It's great stuff! You can read it at http://progexpr.blogspot.com/2006/12/erlyweb-tutorial-part-2.html.
Monday, December 11, 2006
A General Theory of Programming Language Relativity
I don't usually write responses to other articles because, frankly, I think people spend too much time writing articles and too little time writing open source Erlang code that I can use without paying those do-gooder souls a dime for their efforts :) However, this one -- "No Silver Bullet" and Functional Programming -- piqued my curiosity because it discusses functional programming in a positive light and it mentions Erlang a bunch of times. Clearly, the author has gotten *something* right :)
I actually think the author did a pretty good job at explaining some of the benefits of functional programming. The main issue I have with the article is that, as past in other articles I've seen, it puts too much weight on conciseness as an indicator of expressiveness. Although conciseness often contributes to expressiveness, conciseness isn't the only measure of expressiveness. It it were, the commenter who wrote that Python generally has a similar conciseness multiplier to C++ as Haskell, debunking this shootout's conclusion that functional languages are "better" (i.e. more expressive), would have a strong argument.
Both the author and the commenter are making valid points, but I think they are overlooking an aspect of language expressiveness that's at least as important, if not more important, for code quality as conciseness: readability. The reason is pretty obvious: code communicates a solution to a problem not just to computers, but also to humans. If code written in a given language is unduly hard to understand, its conciseness doesn't hold much value because the pain of debugging and maintaining it outweights the ease of writing it. I think it's safe to say that most programmers would prefer to work with a 1500 line solution that's highly readable than a 1000 line solution that's hard to comprehend.
So how does this relate to the functional vs. imperative programming debate? Although functional languages (I'm talking primarily about Erlang because that's the functional language I know best) don't always trump OO/imperative ones in conciseness, their code does generally wins hands down in readability.
This is especially true when comparing functional languages to dynamically-typed OO languages, whose code for anything beyond short scripts is borderline unreadable IMO. Dynamically typed OO languages trade a large degree of readability for conciseness, and that's why Java code, as bloated as it often is, is often more readable than Python and Ruby code. The reason is in the fundamental design (flaw?) of OO languages: they encourage the programmer to bind functions to data (they name the child of this unhealthy marriage an 'object' to make us think this chimera models something from the "real world" :) ), and then use data objects to indirectly invoke bound (virtual) functions. If the type of an object isn't evident in the source code, it's difficult to figure out what functions are called when you read statements such as "obj.doSomething(param)". Due to the abundance of indirect function calls in OO code, dynamically typed OO languages require extra discipline by the programmer to carefully document the types of all variables in his/her code so that other people have a chance to understand what functions are being called.
In my relatively brief encounter with Python, I ran into a bunch of code containing seemingly innocent idioms such as the following (I apologize in advance for Python syntax errors):
Because I has no idea what the types of 'channel' and 'msg' are (the code was poorly documented), what such snippets did was a veritable mystery. After wallowing for hours at a time in such nebulae, trying arduously to trace back to the instantiation points of mysterious parameters, where I would hope to find the golden nuggets of information indicating what types their variables are holding, my frustration would reach such uncomfortable levels that I wouldn't know anymore whether to feel angry or deeply depressed.
When you read Erlang code -- even with scant documentation -- you don't normally have go through such troubles. Although Erlang is dynamically typed, Erlang code avoids such readability black holes because it doesn't throw so much type information out the window. In Erlang, the above snippet would be written as follows:
The Erlang code is less concise, but it's also more readable. (It's also more optimized because it doesn't require the resolution of function pointers in runtime.) In a large code base, this added readability wins over conciseness because it can make difference between providing continuous service and begging your users to come back in a few more hours as you're chasing the mysterious bug that has taken your system offline. It also helps you develop new features faster because you can spend less time debugging and more time coding.
At this point, you may be thinking, "The extra type information in Erlang code has a cost because it sacrifices generality." If you need to write generic code, you can use Erlang's remote function invocation as follows:
This example is admittedly silly, but as you can see, Erlang lets you parameterize module names (and function names) in generic code. This capability is often very useful. Even with remote invocation, the vast majority of Erlang code I've read contains enough type information to be much more readable than imperative/OO code.
In addition to the general absence of mystery functions (for a counter-example, check out ErlyDB :) ), Erlang, and other functional languages such as Haskell, have two language features that make them more readable than imperative languages: pattern-matching and immutability.
How do these features enhance readability and therefore expressiveness? Pattern-matching is easy -- just compare the following snippets:
Erlang:
Imperative, dynamic pseudo-language:
Update (12/12/06): If you read Anders' comment, you'll see that code such as above can be written more succinctly in Python. Please take this example as an illustration of how Erlang pattern matching engine works rather than as a suggestion that there's no better way of writing such code in any imperative language.
I hope this example makes the benefits of pattern-matching obvious :) So, let's look single-assignment, which is another functional programming feature that I have learned to appreciate as an essential contributor to code quality. In Erlang, when you bind a value to a variable, this binding holds for the life of the variable. For instance, in Erlang, if you wrote code such as
the second expression would throw an error. If you're used to Erlang, the reason is quite natural: the first line states that X equals 1, and therefore the following line, stating that X equals 2, is wrong. To someone who isn't used to functional programming, the benefits of this behavior may not be obvious -- it may even seem like a burdensome restriction (I used to think so too). However, over time I learned that single-assignment often makes for drastically more readable code. For example, consider this snippet in an imperative/OO/dynamic language:
out(name, paradigm) {
var l = new Language(name, paradigm);
// much code below
...
l = bar(l);
// much code below
...
return l.getName() + "/" + l.getParadigm();
}
Now answer the following question: what does 'out("Ruby", "imperative")' return? Clearly, you have no way of knowing. In fact, even reading the all the code for the 'foo' function won't help you much -- you'd have to read the code for 'bar' (and any other function that take 'l' as a parameter) in order to have a better clue. Sadly, all that reading still wouldn't guarantee anything if the value of 'l' changes during execution based on some IO input. And that's not the end of it: to make things worse, your life would be even much more miserable if the author of the code decided to venture into the dangerous terrain of multi-threaded programming. If 'l' is shared between different threads, your code comprehension efforts would be that much closer to hopeless.
If this code were written in Erlang, the answer would be simple: the function 'foo' returns a string of value "Ruby/imperative". In small code snippets, such as the ones used in most language comparisons, the readability benefits of single-assignment may not be obvious. However, in a large-scale production systems with high availability requirements written by large teams of developers, the ability to answer questions about unfamiliar code segments is essential for both readability and (automated and non-automated) debugging. Erlang was designed to build such systems, so it makes sense that Erlang shuns mutable variables. (I imagine Ericsson would be in a rather uncomfortable position if a portion of England's phone network went offline because some programmer thought to himself, "the variable 'l' holds an object of type 'Language'!" :) )
So where does all this lead us? Is there a precise way of measuring language expressiveness that takes into account both conciseness and readability? Well, after thinking about this stuff for a while, I arrived at an elegant equation for arriving at an objective quantitative measure of a language's expressiveness. Without further ado, here is my equation for the General Theory of Programming Language Expressiveness:
E = C*R^2
where
E is expressiveness
C is conciseness
R is readability
Now I just need to figure out how to factor in the speed of light. If I succeed, it would undoubtedly pave the way for the Nobel :)
Well, I hope I was able to shed some light on why readability is at least as important as conciseness when evaluating language expressiveness, and also why code written in functional languages (primarily Erlang) enjoys greater readability -- and often, conciseness -- than code written in imperative/OO languages. Now consider this: even if imperative/OO languages were just as concise and readable as Erlang, Erlang code would nonetheless have a higher average quality. Sounds bizzare? Maybe, but it's true :) The reason is that no matter how good a language is, bugs always creep into non-trivial systems, and Erlang is the only language I know that has truly effective mechanisms for dealing with defects that do affect live systems. The idea behind Erlang's approach to fault-tolerance is actually quite simple: a crash in one process doesn't bring down the whole system, and furthermore it's detected by a supervising process that's configured with rules telling it what action to take (e.g. restart the process) when a crash does occur. When you've fixed that pesky bug that has been causing intermittent (yet non-catastrophic!) crashes, you can hot swap the new code into the live system without taking if offline. Due to Erlang's fault tolerant design, 1000 lines of Erlang code with 7 bugs are in a sense "better" than 1000 lines of Java doing exactly the same thing and containing an equal number of bugs. Unfortunately, comparisons that count only line numbers don't show this side of the story.
If none of this convinces you that functional languages are worth using, maybe this tip the paradigm balance in your mind: I've never met a programmer who's versed in both functional programming and OO/imperative programming and who prefers the latter.
But maybe I just need to get more friends :)
I actually think the author did a pretty good job at explaining some of the benefits of functional programming. The main issue I have with the article is that, as past in other articles I've seen, it puts too much weight on conciseness as an indicator of expressiveness. Although conciseness often contributes to expressiveness, conciseness isn't the only measure of expressiveness. It it were, the commenter who wrote that Python generally has a similar conciseness multiplier to C++ as Haskell, debunking this shootout's conclusion that functional languages are "better" (i.e. more expressive), would have a strong argument.
Both the author and the commenter are making valid points, but I think they are overlooking an aspect of language expressiveness that's at least as important, if not more important, for code quality as conciseness: readability. The reason is pretty obvious: code communicates a solution to a problem not just to computers, but also to humans. If code written in a given language is unduly hard to understand, its conciseness doesn't hold much value because the pain of debugging and maintaining it outweights the ease of writing it. I think it's safe to say that most programmers would prefer to work with a 1500 line solution that's highly readable than a 1000 line solution that's hard to comprehend.
So how does this relate to the functional vs. imperative programming debate? Although functional languages (I'm talking primarily about Erlang because that's the functional language I know best) don't always trump OO/imperative ones in conciseness, their code does generally wins hands down in readability.
This is especially true when comparing functional languages to dynamically-typed OO languages, whose code for anything beyond short scripts is borderline unreadable IMO. Dynamically typed OO languages trade a large degree of readability for conciseness, and that's why Java code, as bloated as it often is, is often more readable than Python and Ruby code. The reason is in the fundamental design (flaw?) of OO languages: they encourage the programmer to bind functions to data (they name the child of this unhealthy marriage an 'object' to make us think this chimera models something from the "real world" :) ), and then use data objects to indirectly invoke bound (virtual) functions. If the type of an object isn't evident in the source code, it's difficult to figure out what functions are called when you read statements such as "obj.doSomething(param)". Due to the abundance of indirect function calls in OO code, dynamically typed OO languages require extra discipline by the programmer to carefully document the types of all variables in his/her code so that other people have a chance to understand what functions are being called.
In my relatively brief encounter with Python, I ran into a bunch of code containing seemingly innocent idioms such as the following (I apologize in advance for Python syntax errors):
respond(channel, msg):
if channel.isValid() and msg.body().equals("next"):
return channel.send("A2-B3")
else:
return channel.send("bye")
Because I has no idea what the types of 'channel' and 'msg' are (the code was poorly documented), what such snippets did was a veritable mystery. After wallowing for hours at a time in such nebulae, trying arduously to trace back to the instantiation points of mysterious parameters, where I would hope to find the golden nuggets of information indicating what types their variables are holding, my frustration would reach such uncomfortable levels that I wouldn't know anymore whether to feel angry or deeply depressed.
When you read Erlang code -- even with scant documentation -- you don't normally have go through such troubles. Although Erlang is dynamically typed, Erlang code avoids such readability black holes because it doesn't throw so much type information out the window. In Erlang, the above snippet would be written as follows:
respond(Channel, Msg) ->
case Channel#chess_channel.is_valid && Msg#chess_msg.body == next of
true -> chess_channel:send(Channel, {move, a2, b3});
false -> chess_channel:send(Channel, bye)
end
The Erlang code is less concise, but it's also more readable. (It's also more optimized because it doesn't require the resolution of function pointers in runtime.) In a large code base, this added readability wins over conciseness because it can make difference between providing continuous service and begging your users to come back in a few more hours as you're chasing the mysterious bug that has taken your system offline. It also helps you develop new features faster because you can spend less time debugging and more time coding.
At this point, you may be thinking, "The extra type information in Erlang code has a cost because it sacrifices generality." If you need to write generic code, you can use Erlang's remote function invocation as follows:
respond(ChannelType, Channel, MsgType, Msg) ->
case ChannelType:is_valid(Channel) && MsgType:body(Msg) == "ok" of
true -> ChannelType:send(Channel, {move, a2, b3});
false -> ChannelType:send(Channel, bye)
end.
This example is admittedly silly, but as you can see, Erlang lets you parameterize module names (and function names) in generic code. This capability is often very useful. Even with remote invocation, the vast majority of Erlang code I've read contains enough type information to be much more readable than imperative/OO code.
In addition to the general absence of mystery functions (for a counter-example, check out ErlyDB :) ), Erlang, and other functional languages such as Haskell, have two language features that make them more readable than imperative languages: pattern-matching and immutability.
How do these features enhance readability and therefore expressiveness? Pattern-matching is easy -- just compare the following snippets:
Erlang:
foo({bar, [baz, boing], "18"}) -> ok;
foo(_) -> error.
Imperative, dynamic pseudo-language:
foo(arr) {
if (arr instanceof Array &&
arr.length == 3 &&
arr[0] == 'bar' &&
arr[1] instanceof List &&
arr[1].size() == 2 &&
arr[1].element(0) == 'baz' &&
arr[1].element(1) == 'boing') &&
arr[2] instanceof String &&
arr[2].equals("18"))
return 'ok';
else
return 'error';
}
Update (12/12/06): If you read Anders' comment, you'll see that code such as above can be written more succinctly in Python. Please take this example as an illustration of how Erlang pattern matching engine works rather than as a suggestion that there's no better way of writing such code in any imperative language.
I hope this example makes the benefits of pattern-matching obvious :) So, let's look single-assignment, which is another functional programming feature that I have learned to appreciate as an essential contributor to code quality. In Erlang, when you bind a value to a variable, this binding holds for the life of the variable. For instance, in Erlang, if you wrote code such as
foo() ->
X = 1,
X = 2.
the second expression would throw an error. If you're used to Erlang, the reason is quite natural: the first line states that X equals 1, and therefore the following line, stating that X equals 2, is wrong. To someone who isn't used to functional programming, the benefits of this behavior may not be obvious -- it may even seem like a burdensome restriction (I used to think so too). However, over time I learned that single-assignment often makes for drastically more readable code. For example, consider this snippet in an imperative/OO/dynamic language:
out(name, paradigm) {
var l = new Language(name, paradigm);
// much code below
...
l = bar(l);
// much code below
...
return l.getName() + "/" + l.getParadigm();
}
Now answer the following question: what does 'out("Ruby", "imperative")' return? Clearly, you have no way of knowing. In fact, even reading the all the code for the 'foo' function won't help you much -- you'd have to read the code for 'bar' (and any other function that take 'l' as a parameter) in order to have a better clue. Sadly, all that reading still wouldn't guarantee anything if the value of 'l' changes during execution based on some IO input. And that's not the end of it: to make things worse, your life would be even much more miserable if the author of the code decided to venture into the dangerous terrain of multi-threaded programming. If 'l' is shared between different threads, your code comprehension efforts would be that much closer to hopeless.
If this code were written in Erlang, the answer would be simple: the function 'foo' returns a string of value "Ruby/imperative". In small code snippets, such as the ones used in most language comparisons, the readability benefits of single-assignment may not be obvious. However, in a large-scale production systems with high availability requirements written by large teams of developers, the ability to answer questions about unfamiliar code segments is essential for both readability and (automated and non-automated) debugging. Erlang was designed to build such systems, so it makes sense that Erlang shuns mutable variables. (I imagine Ericsson would be in a rather uncomfortable position if a portion of England's phone network went offline because some programmer thought to himself, "the variable 'l' holds an object of type 'Language'!" :) )
So where does all this lead us? Is there a precise way of measuring language expressiveness that takes into account both conciseness and readability? Well, after thinking about this stuff for a while, I arrived at an elegant equation for arriving at an objective quantitative measure of a language's expressiveness. Without further ado, here is my equation for the General Theory of Programming Language Expressiveness:
E = C*R^2
where
E is expressiveness
C is conciseness
R is readability
Now I just need to figure out how to factor in the speed of light. If I succeed, it would undoubtedly pave the way for the Nobel :)
Well, I hope I was able to shed some light on why readability is at least as important as conciseness when evaluating language expressiveness, and also why code written in functional languages (primarily Erlang) enjoys greater readability -- and often, conciseness -- than code written in imperative/OO languages. Now consider this: even if imperative/OO languages were just as concise and readable as Erlang, Erlang code would nonetheless have a higher average quality. Sounds bizzare? Maybe, but it's true :) The reason is that no matter how good a language is, bugs always creep into non-trivial systems, and Erlang is the only language I know that has truly effective mechanisms for dealing with defects that do affect live systems. The idea behind Erlang's approach to fault-tolerance is actually quite simple: a crash in one process doesn't bring down the whole system, and furthermore it's detected by a supervising process that's configured with rules telling it what action to take (e.g. restart the process) when a crash does occur. When you've fixed that pesky bug that has been causing intermittent (yet non-catastrophic!) crashes, you can hot swap the new code into the live system without taking if offline. Due to Erlang's fault tolerant design, 1000 lines of Erlang code with 7 bugs are in a sense "better" than 1000 lines of Java doing exactly the same thing and containing an equal number of bugs. Unfortunately, comparisons that count only line numbers don't show this side of the story.
If none of this convinces you that functional languages are worth using, maybe this tip the paradigm balance in your mind: I've never met a programmer who's versed in both functional programming and OO/imperative programming and who prefers the latter.
But maybe I just need to get more friends :)
Tuesday, December 05, 2006
ErlyWeb Tutorial by Brian Olsen
Brian Olsen has written a very nice tutorial showing how to create a simple blog application in ErlyWeb. You can read it at http://progexpr.blogspot.com/2006/12/erlyweb-blog-tutorial.html.
It seems that many developers who haven't used Erlang have the perception that it's only good for scaling and concurrency, so it's great to see other people appreciate Erlang (and ErlyWeb) for one if its greatest strengths: simplicity. He's what Brian wrote:
This is just what I've been trying to achieve with ErlyWeb. I'm happy to see this validation that my efforts have borne fruit.
When I was in Sweden, Joe Armstrong told me (tongue in cheek) that one thing he likes about the Erlang conference is that being surrounded by like-minded people gives you a strong indication that you're not insane.
Bring those indications on :)
It seems that many developers who haven't used Erlang have the perception that it's only good for scaling and concurrency, so it's great to see other people appreciate Erlang (and ErlyWeb) for one if its greatest strengths: simplicity. He's what Brian wrote:
I hope you are seeing what I am seeing. ErlyWeb has INCREDIBLE POTENTIAL, since it avoids a lot of complexity. Any gaps we found thus far were easily plugged in. Even though ErlyWeb is new, this, so far, blows Rails out of the water in terms of brevity.
This is just what I've been trying to achieve with ErlyWeb. I'm happy to see this validation that my efforts have borne fruit.
When I was in Sweden, Joe Armstrong told me (tongue in cheek) that one thing he likes about the Erlang conference is that being surrounded by like-minded people gives you a strong indication that you're not insane.
Bring those indications on :)
Monday, November 27, 2006
Europe, November 2006
I'm here in Barcelona, where I will stay for a few more days until the end of my trip. I've had a great time, but I can't wait to get back home. It feels like it's time to go back to regular life.
I started in Stockholm, then I went to Copenhagen, Paris, Lyon, Granada, Seville and Barcelona. I spent a few days in most of these cities, where I mostly did a lot of walking around and sight-seeing. I visited a few museums, but I didn't want to spend too much time in museums because I tend to enjoy more wandering around the streets of a new city, soaking in their sights, smells, and sounds.
Seeing a number of artistic creations that are generally regarded as masterpieces has led me to think about where great software stands in the realm of creative endeavors. As in most fields, some software is great and some isn't, but how come most people don't value great software in the same way that they value great music, paintings or architecture? This question can be discussed in great lengths, but I think the answer boils down to the following points: software can only be understood by programmers -- to non-programmers, all code looks like the same gibberish (much code looks like gibberish to coders as well :) ); software is always utilitarian -- practically all software is written as a means to an end, not an an end in itself; software stimulates the left brain exclusively -- it doesn't trigger a gut reaction like other art forms because its appreciation always requires analytical thinking; most people don't care about how an application or a software library is written -- they just want it to work.
So, maybe great software will never be regarded as art, but I think most people would agree that software development is a craft that requires skill and creativity. In addition, all programmers would agree that some code is beautiful and some isn't. I think the field that resembles software the most in the way we regard its creations isn't sculpture, painting, or music, but math. Like software, math is arcane, complex, logical, and most of it is boring, but many mathematical proofs are among the greatest achievements of our civilization.
Ok, enough philosophising -- let's get back to my travels :)
I went on this trip because I had a strong itch to see more of Europe. It's safe to say that this desire is now quite satisfied. By the last week or so of my trip, I had actually gotten pretty tired of traveling. Although the cities I've visited have plenty of unique charm, visiting a sequence of cities for a few days each ends up feeling repetitive. It would probably be more rewarding to stay in one place for a longer time period, where I would get a richer exposure to the local language and culture. But then again, 3.5 weeks probably isn't enough time for a profound cultural experience, anyway. I would have to stay in a foreign country for at least a few months in order to learn the local language and feel a stronger connection to the place and its people.
(It may even require a longer period to make proper Cultural Learnings of Europe for Make Benefit Glorious Nation of U, S and A : ) )
I actually think I've had my fix of city traveling for a while. Looking back at my trips, I have enjoyed nature vacations more than anything, and there are plenty of natural treasures nearby, including many of the US national parks, that I haven't yet visited. Next time, I will try to plan a nice nature adventure.
When I get back home, I will have to plan the next phase of my career. I have a number of ideas for cool Erlang apps, and also a few offers for different kinds of gigs, but I haven't picked a concrete direction yet. I will certainly keep working on ErlyWeb (there are a number of small improvements I will make as soon as I get home), but I think ErlyWeb is quite good as it is and I don't want it to make it bloated by adding too many features to it. (One aspect of ErlyWeb that could definitely use some work is support for additional database drivers in ErlyDB, but I will probably let other developers lead this effort because I don't have a strong need for other drivers right now.) I will also try to build at least one of the apps I have thought up and see how far I can take it. If all goes well, it will become the next YouTube. If not, I hope it will at least merit a line or two on my resume :)
Boston, get ready to make room for one more person :)
I started in Stockholm, then I went to Copenhagen, Paris, Lyon, Granada, Seville and Barcelona. I spent a few days in most of these cities, where I mostly did a lot of walking around and sight-seeing. I visited a few museums, but I didn't want to spend too much time in museums because I tend to enjoy more wandering around the streets of a new city, soaking in their sights, smells, and sounds.
Seeing a number of artistic creations that are generally regarded as masterpieces has led me to think about where great software stands in the realm of creative endeavors. As in most fields, some software is great and some isn't, but how come most people don't value great software in the same way that they value great music, paintings or architecture? This question can be discussed in great lengths, but I think the answer boils down to the following points: software can only be understood by programmers -- to non-programmers, all code looks like the same gibberish (much code looks like gibberish to coders as well :) ); software is always utilitarian -- practically all software is written as a means to an end, not an an end in itself; software stimulates the left brain exclusively -- it doesn't trigger a gut reaction like other art forms because its appreciation always requires analytical thinking; most people don't care about how an application or a software library is written -- they just want it to work.
So, maybe great software will never be regarded as art, but I think most people would agree that software development is a craft that requires skill and creativity. In addition, all programmers would agree that some code is beautiful and some isn't. I think the field that resembles software the most in the way we regard its creations isn't sculpture, painting, or music, but math. Like software, math is arcane, complex, logical, and most of it is boring, but many mathematical proofs are among the greatest achievements of our civilization.
Ok, enough philosophising -- let's get back to my travels :)
I went on this trip because I had a strong itch to see more of Europe. It's safe to say that this desire is now quite satisfied. By the last week or so of my trip, I had actually gotten pretty tired of traveling. Although the cities I've visited have plenty of unique charm, visiting a sequence of cities for a few days each ends up feeling repetitive. It would probably be more rewarding to stay in one place for a longer time period, where I would get a richer exposure to the local language and culture. But then again, 3.5 weeks probably isn't enough time for a profound cultural experience, anyway. I would have to stay in a foreign country for at least a few months in order to learn the local language and feel a stronger connection to the place and its people.
(It may even require a longer period to make proper Cultural Learnings of Europe for Make Benefit Glorious Nation of U, S and A : ) )
I actually think I've had my fix of city traveling for a while. Looking back at my trips, I have enjoyed nature vacations more than anything, and there are plenty of natural treasures nearby, including many of the US national parks, that I haven't yet visited. Next time, I will try to plan a nice nature adventure.
When I get back home, I will have to plan the next phase of my career. I have a number of ideas for cool Erlang apps, and also a few offers for different kinds of gigs, but I haven't picked a concrete direction yet. I will certainly keep working on ErlyWeb (there are a number of small improvements I will make as soon as I get home), but I think ErlyWeb is quite good as it is and I don't want it to make it bloated by adding too many features to it. (One aspect of ErlyWeb that could definitely use some work is support for additional database drivers in ErlyDB, but I will probably let other developers lead this effort because I don't have a strong need for other drivers right now.) I will also try to build at least one of the apps I have thought up and see how far I can take it. If all goes well, it will become the next YouTube. If not, I hope it will at least merit a line or two on my resume :)
Boston, get ready to make room for one more person :)
Monday, November 13, 2006


{kind=link}
Saturday, November 11, 2006
12th Erlang User Conference
Here I am at Stockholm, Sweden, blogging a day after the 12th International Erlang User Conference.
I had a blast.
I arrived here a few days ago after a long journey from Boston via Paris. A few days before I left, Joe Armstrong generously offered to host me. Accepting the invitation couldn't have been any easier -- I don't get to stay very often for 3 days with the creator of my favorite programming language :).
Spending time with Joe was great. We had many interesting conversations about Erlang, computer science, culture, business, politics, design, and life. It was a rare opportunity to befriend someone who has accomplished so much and who has such a wealth of knowledge and ideas about the fields in which I'm most interested.
Joe is passionate about concurrent programming and the design of fault tolerant systems. This is how he summarized the main ideas behind Erlang (I'm probably paraphrasing): "To build a fault tolerant system, you need at least two computers. Why? Because one of them can crash. If you have more than one computer, you need distributed programming. Distributed applications run in different threads, and therefore concurrency is an integral part of fault tolerant systems."
Many of the presentations were very interesting, but the best part (at least for me) was meeting all the Erlangers I knew only from email correspondence, among whom are Claes (Klacke) Wikstrom, Mickael Remond (the founder of Process One), Ulf Wiger, Robert Virding and many others.
Everyone I met was very friendly, intelligent, down-to-earth, and had a healthy sense of humor. They all love programming in Erlang.
I had a great time chatting with Klacke. Klacke has had one of the most impressive careers of anyone I've ever met. He's created Mnesia, Yaws, distributed Erlang, and many parts of the Erlang emulator. He's also one of the people behind Bluetail, Kreditor, and now tail-f. Klacke constantly comes up with great quotes. Here are a couple of good ones as I remember them: "It feels like I have a sharp knife in my pocket, and other people have a blunt one", "Some problems you can't imagine solving if you don't have the right tools".
I also enjoyed talking with Ulf Wiger, who has developed with Joe Armstrong a very interesting framework for cooperative web development in Erlang called Erlhive. Maybe we will have opportunities for collaboration somwhere down the road.
Finally, I had a nice tour of Stockholm today (but too bad it rained). It's a beautiful city. I walked around the old town and I also visited the Vasa museum, whose exhibit is an impressive warship from the 1600's that capsized due to an engineering blunder: to please the the King's whims, the engineers loaded the ship with too many canons. Due to the excess weight at the top of the ship, it had several glorious minutes of sailing before it sank in the Stockholm harbour. Oops.
I would like to write in more detail, but my jetlag is starting to wear thin and I have to get some sleep as I'm flying to Copenhagen tomorrow. After that, I'm travelling for 3 weeks in Europe, visiting Amsterdam, Paris, Lyon, the south of France, and Spain (mostly Barcelona).
I'll end this posting with few pictures I've taken:

Me, Joe and Mickael Remond

Me and Klacke, A.K.A the Erlang Open Source Web Squad. Our weapons: Erlang, Yaws and ErlyWeb. Our mission: to end web development suckage, one webapp at a time :)
I had a blast.
I arrived here a few days ago after a long journey from Boston via Paris. A few days before I left, Joe Armstrong generously offered to host me. Accepting the invitation couldn't have been any easier -- I don't get to stay very often for 3 days with the creator of my favorite programming language :).
Spending time with Joe was great. We had many interesting conversations about Erlang, computer science, culture, business, politics, design, and life. It was a rare opportunity to befriend someone who has accomplished so much and who has such a wealth of knowledge and ideas about the fields in which I'm most interested.
Joe is passionate about concurrent programming and the design of fault tolerant systems. This is how he summarized the main ideas behind Erlang (I'm probably paraphrasing): "To build a fault tolerant system, you need at least two computers. Why? Because one of them can crash. If you have more than one computer, you need distributed programming. Distributed applications run in different threads, and therefore concurrency is an integral part of fault tolerant systems."
Many of the presentations were very interesting, but the best part (at least for me) was meeting all the Erlangers I knew only from email correspondence, among whom are Claes (Klacke) Wikstrom, Mickael Remond (the founder of Process One), Ulf Wiger, Robert Virding and many others.
Everyone I met was very friendly, intelligent, down-to-earth, and had a healthy sense of humor. They all love programming in Erlang.
I had a great time chatting with Klacke. Klacke has had one of the most impressive careers of anyone I've ever met. He's created Mnesia, Yaws, distributed Erlang, and many parts of the Erlang emulator. He's also one of the people behind Bluetail, Kreditor, and now tail-f. Klacke constantly comes up with great quotes. Here are a couple of good ones as I remember them: "It feels like I have a sharp knife in my pocket, and other people have a blunt one", "Some problems you can't imagine solving if you don't have the right tools".
I also enjoyed talking with Ulf Wiger, who has developed with Joe Armstrong a very interesting framework for cooperative web development in Erlang called Erlhive. Maybe we will have opportunities for collaboration somwhere down the road.
Finally, I had a nice tour of Stockholm today (but too bad it rained). It's a beautiful city. I walked around the old town and I also visited the Vasa museum, whose exhibit is an impressive warship from the 1600's that capsized due to an engineering blunder: to please the the King's whims, the engineers loaded the ship with too many canons. Due to the excess weight at the top of the ship, it had several glorious minutes of sailing before it sank in the Stockholm harbour. Oops.
I would like to write in more detail, but my jetlag is starting to wear thin and I have to get some sleep as I'm flying to Copenhagen tomorrow. After that, I'm travelling for 3 weeks in Europe, visiting Amsterdam, Paris, Lyon, the south of France, and Spain (mostly Barcelona).
I'll end this posting with few pictures I've taken:
Me, Joe and Mickael Remond
Me and Klacke, A.K.A the Erlang Open Source Web Squad. Our weapons: Erlang, Yaws and ErlyWeb. Our mission: to end web development suckage, one webapp at a time :)
Friday, November 03, 2006
ErlyWeb + Yaws 1.64
Some people have had trouble running ErlyWeb on Yaws 1.64. This is because the Yaws 'arg' record has changed. I created a Yaws 1.64 compatible yaws_arg.beam file that you can download here. If you're running Yaws 1.64, drop this file in place of the existing yaws_arg.beam in in your 'erlyweb-0.x/ebin' directory, give it another try, and let me know if it helped.
Thursday, November 02, 2006
New ErlyWeb Google Group
Following the suggestion of one of my readers, I created a Google group for ErlyWeb hackers. You can join it to ask questions, share points of view, help each other out, make suggestions, and announce the launch of the killer ErlyWeb app you're building :)
Here's the link: http://groups.google.com/group/erlyweb
From now on, I will make all announcements about new releases in this group rather than on my blog.
Here's the link: http://groups.google.com/group/erlyweb
From now on, I will make all announcements about new releases in this group rather than on my blog.
ErlyWeb 0.2
I made some improvements to the first release of ErlyWeb, some based on user feedback, and some based on my own whims :) This is what I did:
- Chaged the LastCompileTime parameter in erlyweb:compile into an option value in the form of {last_compile_time, Time}.
- Added the following options to erlyweb:compile/2:
{auto_compile, true} : this option, useful during development, tells ErlyWeb to compile all files that have changed since the last request when a new request arrives. This frees you from having to call erlyweb:compile every time you make a code change in your app. Just don't forget to turn auto-compilation off by calling erlyweb:compile without the {auto_compile, true} option when you are switching from development to production mode, because auto-compilation slows things down.
Update (12/6/06): The pre_compile_hook and post_compile_hook have changed in ErlyWeb v0.3. Read this announcement for more details.
{pre_compile_hook, {Module, FuncName}} and {post_compile_hook, {Module, FuncName}}: these option tell ErlyWeb to call the predefined functions before/after (auto)compilation. This allows you to extend the compilation process in an arbitrary way, e.g. by compiling additional files that are outside of the application's src directory. Both functions take a single parameter which is the time of the last compilation (or 'undefined' if the time is not available). For example, let's say you have the following file called 'compile_hooks.erl' in the 'src' directory:
You could use the new compilation options as follows:
From now on, every time ErlyWeb does an auto-compilation, it will call those hooks, passing into them the time of the last compilation (or 'undefined' on the first compilation).
- Changed the include directive in yaws_arg.erl from '-include("yaws/include/yaws_api.hrl").' to '-include("yaws_api.hrl").' (this removes assumptions about your Yaws path structure).
- Changed the docroot directive in yaws from pointing at the application's base directory to [base]/www. E.g., if your previous docroot line was
docroot = /apps/music
it should now be
docroot = /apps/music/www
(there's no change in behavior -- it just makes the configuration more explicit).
That's it :)
Note: a few people have asked me whether ErlyWeb requires a MySQL database. The answer is 'no.' You can use ErlyWeb without any database backend. Just don't keep the source files for any models in src/components, and then you'll never even have to call erlydb:start().
In a minute, I'll put the new zip file on erlyweb.org so you can download it all in one shot.
- Chaged the LastCompileTime parameter in erlyweb:compile into an option value in the form of {last_compile_time, Time}.
- Added the following options to erlyweb:compile/2:
{auto_compile, true} : this option, useful during development, tells ErlyWeb to compile all files that have changed since the last request when a new request arrives. This frees you from having to call erlyweb:compile every time you make a code change in your app. Just don't forget to turn auto-compilation off by calling erlyweb:compile without the {auto_compile, true} option when you are switching from development to production mode, because auto-compilation slows things down.
Update (12/6/06): The pre_compile_hook and post_compile_hook have changed in ErlyWeb v0.3. Read this announcement for more details.
{pre_compile_hook, {Module, FuncName}} and {post_compile_hook, {Module, FuncName}}: these option tell ErlyWeb to call the predefined functions before/after (auto)compilation. This allows you to extend the compilation process in an arbitrary way, e.g. by compiling additional files that are outside of the application's src directory. Both functions take a single parameter which is the time of the last compilation (or 'undefined' if the time is not available). For example, let's say you have the following file called 'compile_hooks.erl' in the 'src' directory:
-module(compile_hooks).
-compile(export_all).
pre_compile(LastCompileTime) ->
io:format("pre-compile (last: ~p) ~n", [LastCompileTime]).
post_compile(LastCompileTime) ->
io:format("post-compile (last: ~p) ~n", [LastCompileTime]).
You could use the new compilation options as follows:
erlyweb:compile("/path/to/app",
[{erlydb_driver, mysql},
{auto_compile, true},
{pre_compile_hook, {compile_hooks, pre_compile}},
{post_compile_hook, {compile_hooks, post_compile}}]).
From now on, every time ErlyWeb does an auto-compilation, it will call those hooks, passing into them the time of the last compilation (or 'undefined' on the first compilation).
- Changed the include directive in yaws_arg.erl from '-include("yaws/include/yaws_api.hrl").' to '-include("yaws_api.hrl").' (this removes assumptions about your Yaws path structure).
- Changed the docroot directive in yaws from pointing at the application's base directory to [base]/www. E.g., if your previous docroot line was
docroot = /apps/music
it should now be
docroot = /apps/music/www
(there's no change in behavior -- it just makes the configuration more explicit).
That's it :)
Note: a few people have asked me whether ErlyWeb requires a MySQL database. The answer is 'no.' You can use ErlyWeb without any database backend. Just don't keep the source files for any models in src/components, and then you'll never even have to call erlydb:start().
In a minute, I'll put the new zip file on erlyweb.org so you can download it all in one shot.
Wednesday, November 01, 2006
Goodbye, Typo. Hello Wordpress!
Update (12/21/06): I was in a pretty upset state of mind after struggling with a barely-working comment system for many days when I wrote this posting. I didn't want to take my frustrations out on Typo because I liked Typo (plus, I really didn't think this was Typo's fault because Typo worked fine under light load), so I picked on Rails instead. Please read this posting as a silly angry rant rather than a well thought-out criticism.
It wouldn't be fair to judge the venerable Ruby on Rails "platform" based on a single data point (*cough* it sucks! *cough* *cough*), but after days of agony trying to get comment submission to work properly in Typo (executing an INSERT after an HTTP POST must be a requirement that's outside of Rails' "scope"), I decided to go back to my roots and run this blog on Wordpress.
(Yes, I was tempted to write my own blogging engine in Erlang, but I decided against it -- I must keep my eyes on the prize :) )
Based on my admittedly limited Rails experience, even if Erlang isn't your cup of tea, I recommend avoiding Rails and sticking to PHP or Python (or Smalltalk, about which I hear nice things) unless you're an optimization genius who loves the thrill of Linux tinkering; you're hopelessly stricken by a successful marketing blitz; you're a masochist; you wrote a Rails book; or you're just not planning on success.
I can't comprehend why some people think it's justifiable to ask someone how many worker processes he would like to run. I wouldn't want to pick a low number like, say, 5, because that might indicate that I have self esteem issues, but then I'm trapped by the fear than an astronomically high number such as, gosh, 20, would hose my VPS.
Sometimes, when I let my imagination run wild, I wish I could say something crazy, like "500,000".
Oh wait -- I can :)
Update (11/2): Wow! Wordpress is so much faster than Typo! Good job, Matt! :)
It wouldn't be fair to judge the venerable Ruby on Rails "platform" based on a single data point (*cough* it sucks! *cough* *cough*), but after days of agony trying to get comment submission to work properly in Typo (executing an INSERT after an HTTP POST must be a requirement that's outside of Rails' "scope"), I decided to go back to my roots and run this blog on Wordpress.
(Yes, I was tempted to write my own blogging engine in Erlang, but I decided against it -- I must keep my eyes on the prize :) )
Based on my admittedly limited Rails experience, even if Erlang isn't your cup of tea, I recommend avoiding Rails and sticking to PHP or Python (or Smalltalk, about which I hear nice things) unless you're an optimization genius who loves the thrill of Linux tinkering; you're hopelessly stricken by a successful marketing blitz; you're a masochist; you wrote a Rails book; or you're just not planning on success.
I can't comprehend why some people think it's justifiable to ask someone how many worker processes he would like to run. I wouldn't want to pick a low number like, say, 5, because that might indicate that I have self esteem issues, but then I'm trapped by the fear than an astronomically high number such as, gosh, 20, would hose my VPS.
Sometimes, when I let my imagination run wild, I wish I could say something crazy, like "500,000".
Oh wait -- I can :)
Update (11/2): Wow! Wordpress is so much faster than Typo! Good job, Matt! :)
Tuesday, October 31, 2006
The Correction
If you have finance background (one of my majors was Economics, the others were Math and Computer Science -- but I liked Math the most, especially probability theory), you should know that markets often price equities irrationally. That's due to the crowd mentality that tends to possess investors: instead of buying the bargain stocks that other investors overlook and that give great returns in the long run, they chase the hyped stocks that get all the news coverage, only to eventually see their prices crash and burn.
Although such bubbles happen periodically, they are always followed by a correction: the market wakes up and realizes that it placed incorrect values on certain stocks, leading to the nose-dive of their prices, whereas other stocks rise from obscurity as investors realize what great values they are.
I think we're finally starting to see a correction in the more interesting field (at least, to me) of programming languages :)

Although such bubbles happen periodically, they are always followed by a correction: the market wakes up and realizes that it placed incorrect values on certain stocks, leading to the nose-dive of their prices, whereas other stocks rise from obscurity as investors realize what great values they are.
I think we're finally starting to see a correction in the more interesting field (at least, to me) of programming languages :)
Monday, October 30, 2006
New ErlyWeb Zip file
I created a zip file containing ErlyWeb 0.1 and its libraries for easy installation. Check out erlyweb.org for more info.
ErlyWeb Visitor Map, Day 1
Here it is, straight from Google Analytics:
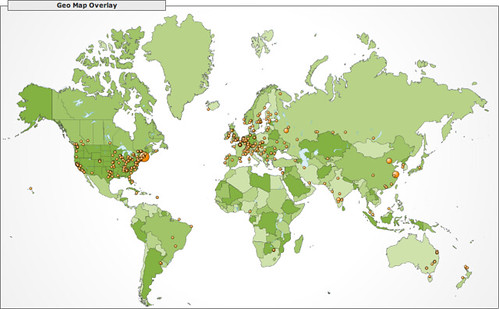
Apparently, Klacke and I aren't the only ones who think that web development doesn't have to suck :)
(Correction: this is the accumulated result for days 1-3, undercounted due to AJAX dependence.)
Apparently, Klacke and I aren't the only ones who think that web development doesn't have to suck :)
(Correction: this is the accumulated result for days 1-3, undercounted due to AJAX dependence.)
Friday, October 27, 2006
Introducing ErlyWeb: The Erlang Twist on Web Frameworks
If you've been reading this blog for a while and you've been connecting the dots, you probably know where this is going... :) I you haven't, that's ok -- my old postings aren't going anywhere. There's a lot of Erlang goodness in them for you to soak up at your leisure as you're getting up to speed on this great language.
Without further ado, I present to you the culmination of all of my exciting adventures thus far in the land of open source Erlang:
ErlyWeb: The Erlang Twist on Web Frameworks.
Don't worry, I'm not going to blab for a long time now about why I think ErlyWeb + Yaws is the best web development toolkit available (not that I'm biased or anything :) ). Instead, I decided I'll just take you on a quick tour of how to use ErlyWeb, and let you use your own knowledge about Erlang to fill in the gaps :)
- Get the latest ErlyWeb archive from erlyweb.org, unzip it, and put the zip file's contents in your Erlang code path. (The Erlang code path is the root directory within which the Erlang VM searches for compiled modules. In OS X, it's "/usr/local/lib/erlang/lib". For more information, visit http://www.erlang.org/doc/doc-5.5.4/lib/kernel-2.11.4/doc/html/code.html).
- Download and install Yaws if you don't already have it.
- Start Yaws in interactive mode ("yaws -i") and type in the Yaws shell
(I'm assuming that "/apps" is the parent directory of your Yaws apps.)
This will create an ErlyWeb directory structure as well as a few files. (Note: this initial procedure will probably be shorter when ErlyWeb matures.) This is what you should see:
- Edit your yaws.conf file by adding a server configuration with the following docroot, appmod, and opaque directives, then type "yaws:restart()."
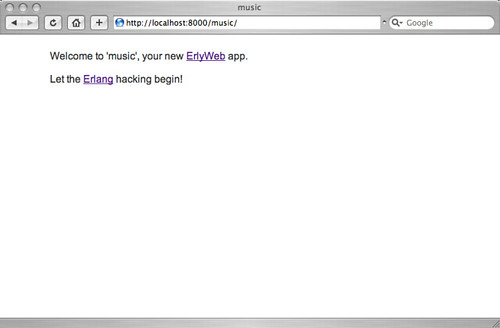
- Open your browser and point it at http://localhost:8000/music (note: your host/port may be different, depending on your Yaws configuration). You should see the following page, (breathtaking in its design and overflowing with aesthetic genius, if I may add):
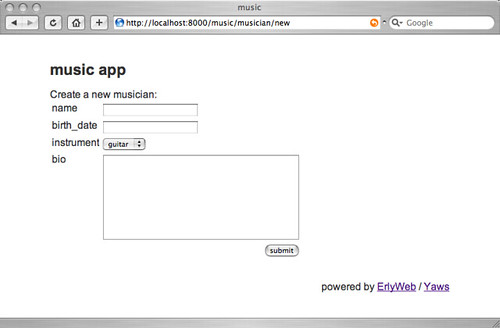
- Create a MySQL database called 'music' with the following code (thanks, Wikipedia :) ):
- Back in Yaws, type
This will create the following files:
/apps/music/components/musician.erl
/apps/music/components/musician_controller.erl
/apps/music/components/musician_view.erl
Back in Yaws, type
(The erlydb_driver option tells ErlyWeb which database driver to use for generating ErlyDB code for the models. Note: this may change in a future version.)
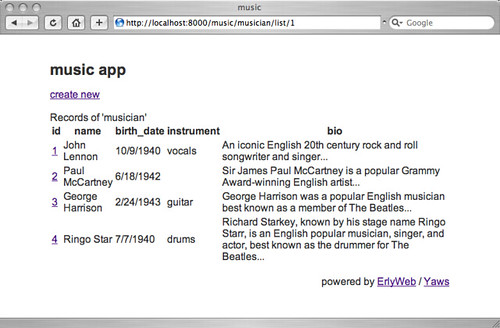
Now go to http://localhost:8000/music/musician, click around, and you'll see the following screens:
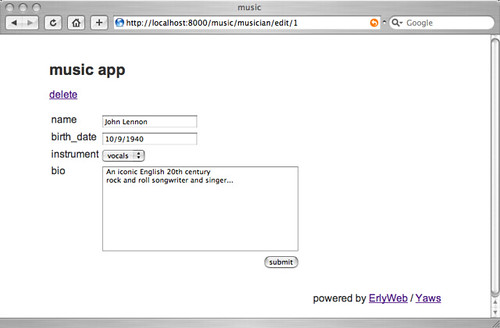
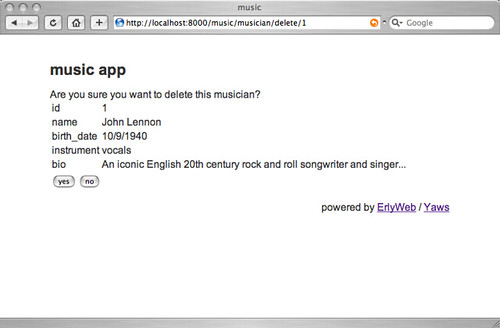
"Aha!" you may be thinking now, "I bet he's using some Smerl trickery to call functions that contain mountains of horrible code only comprehensible to Swedish Field Medal winners!"
Well.. um, not exactly. In fact, this is the code for erlyweb_controller.erl
And this is the code for erlyweb_view.et
Not exactly the stuff that would win anyone the Field Medal, if I dare say so.
If ErlyDB hasn't convinced you that Erlang is a very flexible language, I hope that ErlyWeb does. In fact, I don't know of any other language that has Erlang's combination of flexibility, elegance and power. (If such a language existed, I wouldn't be using Erlang :) ).
The flexibility of components
The notion of component reusability is central to ErlyWeb's design. In ErlyWeb, each component is made of a view and a controller, whose files are placed in 'src/components'. All controller functions must accept as their first parameter the Yaws Arg for the HTTP request, and they may return any value that Yaws accepts (yes, even ehtml, but ehtml can't be nested in other components). In addition, they can return a few special values:
So what do all those funny tuples do?
{data, Data} is simple: it tells ErlyWeb to call the corresponding view function by passing it the Data variable as a parameter, and then send result to the browser.
'ewr' stands for 'ErlyWeb redirect.' The various 'ewr' tuples simplify sending Yaws a 'redirect_local' tuple that has the URL for a component/function/parameters combination in the same app:
- {ewr, FuncName} tells ErlyWeb to return to Yaws a redirect_local to a different function in the same component.
- {ewr, Component, FuncName} tells ErlyWeb to return to Yaws a redirect_local to a function from a different component.
- {ewr, Component, FuncName, Params} tells ErlyWeb to return to Yaws a redirect_local to a component function with the given URL parameters.
For example,
{ewr, musician, list, [4]}
will result in a redirect to
http://localhost:8000/music/musician/list/4
'ewc' stands for 'ErlyWeb component.' By returning an 'ewc' tuple, you are effectively telling ErlyWeb, "render the component described by this tuple, and then send the result to the view function for additional rendering." Returning a single 'ewc' tuple is similar to 'ewr', with a few differences:
- 'ewc' doesn't trigger a browser redirect
- the result of the rendering is sent to the view function
- {ewc, Arg} lets you rewrite the arg prior to invoking other controller functions.
(If this sounds complex, don't worry -- it really isn't. Just try it yourself and see how it works.)
Now to the cool stuff: not only can your controller functions return a single 'ewc' tuple, they can also return a (nested) list of 'ewc' tuples. When this happens, ErlyWeb renders all the components in a depth-first order and the sends the final result to the view function. This lets you very easily create components that are composed of other sub-components.
For example, let's say you wanted to make blog sidebar component with several sub-components. You could implement it as follows:
sidebar_controller.erl
'sidebar_view.et'
Pretty cool, huh?
If you don't want your users to be able to access your sub-components directly by navigating to their corresponding URLs, you can implement the following function in your controllers:
This will tell ErlyWeb to reject requests for private components that come from a web client directly.
Each application has one special controller that isn't part of the component framwork. This controller is always named '[AppName]\_app\_controller.erl' and it's placed in the 'src' directory. The app controller has a single function called 'hook/1', whose default implementation is
The app controller hook may return any of the values that normal controller functions return. It is useful for intercepting all requests prior to their processing, letting your rewrite the Arg or explicitly invoke other components (such as a login page).
Well, that's about it for now :) I'll appreciate any feedback, bug reports, useful code contributions, etc.
Final words
After reading all this, some of you may be thinking, "This is weird... I thought Erlang is some scary telcom thing, but what I'm actually seeing here is that Erlang is very simple... Heck, this stuff is even simpler than Rails. What's going on here?"
If that's what you're thinking, then you are right. Erlang *is* simpler than Ruby, and that's why ErlyWeb is naturally simpler than Rails. In fact, Erlang's simplicity is one of its most underrated aspects. Erlang's creators knew very well what they were doing when they insisted on keeping Erlang simple: complexity leads to bugs; bugs lead to downtime; and if there's one thing Erlangers hate the most, it's downtime.
Without further ado, I present to you the culmination of all of my exciting adventures thus far in the land of open source Erlang:
ErlyWeb: The Erlang Twist on Web Frameworks.
Don't worry, I'm not going to blab for a long time now about why I think ErlyWeb + Yaws is the best web development toolkit available (not that I'm biased or anything :) ). Instead, I decided I'll just take you on a quick tour of how to use ErlyWeb, and let you use your own knowledge about Erlang to fill in the gaps :)
- Get the latest ErlyWeb archive from erlyweb.org, unzip it, and put the zip file's contents in your Erlang code path. (The Erlang code path is the root directory within which the Erlang VM searches for compiled modules. In OS X, it's "/usr/local/lib/erlang/lib". For more information, visit http://www.erlang.org/doc/doc-5.5.4/lib/kernel-2.11.4/doc/html/code.html).
- Download and install Yaws if you don't already have it.
- Start Yaws in interactive mode ("yaws -i") and type in the Yaws shell
erlyweb:create_app("music", "/apps").
(I'm assuming that "/apps" is the parent directory of your Yaws apps.)
This will create an ErlyWeb directory structure as well as a few files. (Note: this initial procedure will probably be shorter when ErlyWeb matures.) This is what you should see:
/apps/music
/apps/music/ebin
/apps/music/src/music_app_controller.erl
/apps/music/src/music_app_view.et
/apps/music/src/components
/apps/music/www
/apps/music/www/index.html
/apps/music/www/style.css
- Edit your yaws.conf file by adding a server configuration with the following docroot, appmod, and opaque directives, then type "yaws:restart()."
docroot = /apps/music/www
appmods = <"/music", erlyweb>
appname = music
- Open your browser and point it at http://localhost:8000/music (note: your host/port may be different, depending on your Yaws configuration). You should see the following page, (breathtaking in its design and overflowing with aesthetic genius, if I may add):
- Create a MySQL database called 'music' with the following code (thanks, Wikipedia :) ):
CREATE TABLE musician (
id integer primary key auto_increment,
name varchar(20),
birth_date date,
instrument enum("guitar", "piano",
"drums", "vocals"),
bio text
) type=INNODB;
INSERT INTO musician(name, birth_date,
instrument, bio) VALUES
("John Lennon", "1940/10/9", "vocals",
"An iconic English 20th century
rock and roll songwriter and singer..."),
("Paul McCartney", "1942/6/18", "piano",
"Sir James Paul McCartney
is a popular Grammy Award-winning
English artist..."),
("George Harrison", "1943/2/24", "guitar",
"George Harrison was a popular English
musician best known as a member of The Beatles..."),
("Ringo Star", "1940/7/7", "drums",
"Richard Starkey, known by his stage name
Ringo Starr, is an English popular musician,
singer, and actor, best known as the
drummer for The Beatles...");
- Back in Yaws, type
erlyweb:create_component("musician", "/apps/music").
This will create the following files:
/apps/music/components/musician.erl
-module(musician).
/apps/music/components/musician_controller.erl
-module(musician_controller).
-erlyweb_magic(on).
/apps/music/components/musician_view.erl
-module(musician_view).
-erlyweb_magic(on).
Back in Yaws, type
erlydb:start(mysql, [{hostname, "localhost"}, {username, "username"},
{password, "password"}, {database, "music"}]).
erlyweb:compile("/apps/music", [{erlydb_driver, mysql}]).
(The erlydb_driver option tells ErlyWeb which database driver to use for generating ErlyDB code for the models. Note: this may change in a future version.)
Now go to http://localhost:8000/music/musician, click around, and you'll see the following screens:
"Aha!" you may be thinking now, "I bet he's using some Smerl trickery to call functions that contain mountains of horrible code only comprehensible to Swedish Field Medal winners!"
Well.. um, not exactly. In fact, this is the code for erlyweb_controller.erl
%% @title erlyweb_controller
%% @author Yariv Sadan (yarivsblog@gmail.com, http://yarivsblog.com)
%%
%% @doc This file contains basic CRUD controller logic. It's intended
%% for demonstration purposes, but not for production use.
%%
%% @license For license information see LICENSE.txt
-module(erlyweb_controller).
-author("Yariv Sadan (yarivsblog@gmail.com, http://yarivsblog.com)").
-export([
index/2,
list/2,
list/3,
new/2,
edit/3,
delete/3
]).
-define(RECORDS_PER_PAGE, 10).
index(_A, Model) ->
{ewr, Model, list, [1]}.
list(A, Model) ->
list(A, Model, 1).
list(A, Model, Page) when is_list(Page) ->
list(A, Model, list_to_integer(Page));
list(A, Model, Page) when is_integer(Page) ->
Records = Model:find_range((Page - 1) * ?RECORDS_PER_PAGE,
?RECORDS_PER_PAGE),
%% this function makes the 'edit' links in the record ids
ToIoListFun =
fun(Val, Field) ->
case erlydb_field:name(Field) of
id ->
Id = Model:field_to_iolist(Val),
erlyweb_html:a(
[erlyweb_util:get_app_root(A),
atom_to_list(Model),
<<"edit">>, Id], Id);
_ ->
default
end
end,
{data, {erlyweb_util:get_appname(A),
atom_to_list(Model),
Model:db_field_names_bin(),
Model:to_iolist(Records, ToIoListFun)}}.
new(A, Model) ->
Rec = Model:new(),
new_or_edit(A, Model, Rec).
edit(A, Model, Id) ->
Rec = Model:find_id(Id),
new_or_edit(A, Model, Rec).
new_or_edit(A, Model, Record) ->
Fields = tl(Model:db_fields()),
Vals = tl(Model:to_iolist(Record)),
Combined = lists:zip(Fields, Vals),
IdStr = case Model:id(Record) of
undefined -> [];
Id -> integer_to_list(Id)
end,
case yaws_arg:method(A) of
'GET' ->
FieldData = [{erlydb_field:name_bin(Field),
erlydb_field:html_input_type(Field),
erlydb_field:modifier(Field),
Val} || {Field, Val} <- Combined],
{data, {erlyweb_util:get_app_root(A),
atom_to_list(Model),
IdStr,
yaws_arg:server_path(A),
FieldData}};
'POST' ->
NewVals = yaws_api:parse_post(A),
Record1 = Model:set_fields_from_strs(Record, NewVals),
Model:save(Record1),
{ewr, Model, list}
end.
delete(A, Model, Id) ->
case yaws_arg:method(A) of
'GET' ->
Record = Model:find_id(Id),
Fields = [erlydb_field:name_bin(Field) ||
Field <- Model:db_fields()],
Vals = Model:to_iolist(Record),
Combined =
lists:zipwith(
fun(Field, Val) -> [Field, Val] end,
Fields, Vals),
{data, {erlyweb_util:get_app_root(A),
atom_to_list(Model), Id,
Combined}};
'POST' ->
Model:delete_id(Id),
{ewr, Model, list}
end.
And this is the code for erlyweb_view.et
<%~
%% @title erlyweb_view.et
%% @doc This is a generic view template for making simple CRUD
%% pages with ErlyWeb. It's intended for demonstration purposes,
%% but not for production use.
%%
%% @license for license information see LICENSE.txt
-author("Yariv Sadan (yarivsblog@gmail.com, http://yarivsblog.com)").
-import(erlyweb_html, [a/2, table/1, table/2, form/3]).
%% You can add component-specific headers and footers around the Data
%% element below.
%>
<% Data %>
<%@ list({AppRoot, Model, Fields, Records}) %>
<% a(["", AppRoot, Model, <<"new">>], <<"create new">>) %>
Records of '<% Model %>'
<% table(Records, Fields) %>
<%@ new({_AppRoot, Model, _Id, Action, FieldData}) %>
Create a new <% Model %>:
<% form(Action, <<"new">>, FieldData) %>
<%@ edit({AppRoot, Model, Id, Action, FieldData}) %>
delete
<% form(Action, <<"edit">>, FieldData) %>
<%@ delete({AppRoot, Model, Id, Combined}) %>
Are you sure you want to delete this <% Model %>?
<% table(Combined) %>
method="post">
onclick="location.href='<% AppRoot %>/<% Model%>'"
value="no">
Not exactly the stuff that would win anyone the Field Medal, if I dare say so.
If ErlyDB hasn't convinced you that Erlang is a very flexible language, I hope that ErlyWeb does. In fact, I don't know of any other language that has Erlang's combination of flexibility, elegance and power. (If such a language existed, I wouldn't be using Erlang :) ).
The flexibility of components
The notion of component reusability is central to ErlyWeb's design. In ErlyWeb, each component is made of a view and a controller, whose files are placed in 'src/components'. All controller functions must accept as their first parameter the Yaws Arg for the HTTP request, and they may return any value that Yaws accepts (yes, even ehtml, but ehtml can't be nested in other components). In addition, they can return a few special values:
{data, Data}
{ewr, FuncName}
{ewr, Component, FuncName}
{ewr, Component, FuncName, Params}
{ewc, A}
{ewc, Component, Params}
{ewc, Component, FuncName, Params}
So what do all those funny tuples do?
{data, Data} is simple: it tells ErlyWeb to call the corresponding view function by passing it the Data variable as a parameter, and then send result to the browser.
'ewr' stands for 'ErlyWeb redirect.' The various 'ewr' tuples simplify sending Yaws a 'redirect_local' tuple that has the URL for a component/function/parameters combination in the same app:
- {ewr, FuncName} tells ErlyWeb to return to Yaws a redirect_local to a different function in the same component.
- {ewr, Component, FuncName} tells ErlyWeb to return to Yaws a redirect_local to a function from a different component.
- {ewr, Component, FuncName, Params} tells ErlyWeb to return to Yaws a redirect_local to a component function with the given URL parameters.
For example,
{ewr, musician, list, [4]}
will result in a redirect to
http://localhost:8000/music/musician/list/4
'ewc' stands for 'ErlyWeb component.' By returning an 'ewc' tuple, you are effectively telling ErlyWeb, "render the component described by this tuple, and then send the result to the view function for additional rendering." Returning a single 'ewc' tuple is similar to 'ewr', with a few differences:
- 'ewc' doesn't trigger a browser redirect
- the result of the rendering is sent to the view function
- {ewc, Arg} lets you rewrite the arg prior to invoking other controller functions.
(If this sounds complex, don't worry -- it really isn't. Just try it yourself and see how it works.)
Now to the cool stuff: not only can your controller functions return a single 'ewc' tuple, they can also return a (nested) list of 'ewc' tuples. When this happens, ErlyWeb renders all the components in a depth-first order and the sends the final result to the view function. This lets you very easily create components that are composed of other sub-components.
For example, let's say you wanted to make blog sidebar component with several sub-components. You could implement it as follows:
sidebar_controller.erl
index(A) ->
[{ewc, about, [A]},
{ewc, projects, [A]},
{ewc, categories, [A]},
{ewc, tags, [A]}].
'sidebar_view.et'
<%@ index(Data) %>
Pretty cool, huh?
If you don't want your users to be able to access your sub-components directly by navigating to their corresponding URLs, you can implement the following function in your controllers:
private() -> true.
This will tell ErlyWeb to reject requests for private components that come from a web client directly.
Each application has one special controller that isn't part of the component framwork. This controller is always named '[AppName]\_app\_controller.erl' and it's placed in the 'src' directory. The app controller has a single function called 'hook/1', whose default implementation is
hook(A) -> {ewc, A}.
The app controller hook may return any of the values that normal controller functions return. It is useful for intercepting all requests prior to their processing, letting your rewrite the Arg or explicitly invoke other components (such as a login page).
Well, that's about it for now :) I'll appreciate any feedback, bug reports, useful code contributions, etc.
Final words
After reading all this, some of you may be thinking, "This is weird... I thought Erlang is some scary telcom thing, but what I'm actually seeing here is that Erlang is very simple... Heck, this stuff is even simpler than Rails. What's going on here?"
If that's what you're thinking, then you are right. Erlang *is* simpler than Ruby, and that's why ErlyWeb is naturally simpler than Rails. In fact, Erlang's simplicity is one of its most underrated aspects. Erlang's creators knew very well what they were doing when they insisted on keeping Erlang simple: complexity leads to bugs; bugs lead to downtime; and if there's one thing Erlangers hate the most, it's downtime.
ErlyDB 0.7.1, Revamped Driver 0.9.7, Smerl rev 29
ErlyDB 0.7.1
- Fixed a couple of reported bugs (you can look at the issue tracker for more information).
- Added a bunch of functions for getting field metadata from the database. You can look at erlydb\_base.erl and erlydb\_field.erl for more details.
- Added new functions for converting a record to an iolist and for setting its field values from property lists.
- Fixed a bug in the encoding of single digit date values.
Revamped MySQL Driver 0.9.7
- Fixed a bug whereby failed connection attempts could cause process leaks.
- Changed the translation of database null values from 'null' to 'undefined'.
Smerl rev 29
- Improved the module extension mechanism
- Fixed a couple of reported bugs (you can look at the issue tracker for more information).
- Added a bunch of functions for getting field metadata from the database. You can look at erlydb\_base.erl and erlydb\_field.erl for more details.
- Added new functions for converting a record to an iolist and for setting its field values from property lists.
- Fixed a bug in the encoding of single digit date values.
Revamped MySQL Driver 0.9.7
- Fixed a bug whereby failed connection attempts could cause process leaks.
- Changed the translation of database null values from 'null' to 'undefined'.
Smerl rev 29
- Improved the module extension mechanism
Saturday, October 21, 2006
ErlTL 0.9.1
In the past couple of days, I've done a lot of ErlTL hacking. Here's what I've accomplished:
- I added support full Erlang function declarations. ErlTL now gives you unlimited flexibilty in function declarations. You can decide what the variables are, add guards, and use Erlang's full pattern matching capabilities. With pattern matching, your don't have to rely as much on cumbersome if-else statements. Here's a sample function declaration that's now legal in ErlTL:
- I added support for top-level declarations. At the top of your template file, you can now declare Erlang module attributes, compiler directives, and even complete functions (although the latter is not advised as template files aren't meant to contain logic that's better put in a regular Erlang module). One of main benefits is that now you call functions from other templates with less code by importing them. The new syntax for top-level declarations is '<%~ .. %>'. Here's an example:
- I fixed a bug that caused ErlTL to fail to parse multi-line Erlang expressions.
- I rewrote almost all the code. Yes, the last code worked, but it needed to be prettier :)
And finally, here's an example of a complete ErlTL 0.9.1 template:
Damn -- now I really can't wait to build those killer Erlang webapps! :)
- I added support full Erlang function declarations. ErlTL now gives you unlimited flexibilty in function declarations. You can decide what the variables are, add guards, and use Erlang's full pattern matching capabilities. With pattern matching, your don't have to rely as much on cumbersome if-else statements. Here's a sample function declaration that's now legal in ErlTL:
<%@ foo(Bar, {Baz, Boing} = Data) when is_integer(Bar) %>
- I added support for top-level declarations. At the top of your template file, you can now declare Erlang module attributes, compiler directives, and even complete functions (although the latter is not advised as template files aren't meant to contain logic that's better put in a regular Erlang module). One of main benefits is that now you call functions from other templates with less code by importing them. The new syntax for top-level declarations is '<%~ .. %>'. Here's an example:
<%~
-author("Yariv Sadan").
-import(my_killer_widgets,
[foo/1, bar/1, baz/2]).
%% this is allowed, but not advised
pluralize(Noun) -> [Noun, "s"].
%>
<% foo(Data) %>
- I fixed a bug that caused ErlTL to fail to parse multi-line Erlang expressions.
- I rewrote almost all the code. Yes, the last code worked, but it needed to be prettier :)
And finally, here's an example of a complete ErlTL 0.9.1 template:
<%~
%% date: 10/21/2006
-author("Yariv Sadan").
-import(widgets, [foo/1, bar/2, baz/3]).
%>
<%!
This is a sample ErlTL template that renders a
list of albums in HTML
%>
<% [album(A) || A <- Data] %>
<%@ album({Title, Artist, Songs}) %>
Title: <% Title %>
Artist: <% Artist %>
Songs:
<% [song(Number, Name) || {Number, Name} <- Songs] %>
<%@ song(Number, Name) when size(Name) > 15 %>
<%? <> = Name %>
<% song(Number, [First, <<"...">>]) %>
<%@ song(Number, Name) %>
<%?
Class =
case Number rem 2 of
0 -> <<"even">>;
1 -> <<"odd">>
end
%>
<% integer_to_list(Number) %>
<% Name %>
Damn -- now I really can't wait to build those killer Erlang webapps! :)
Tuesday, October 17, 2006
Introducing ErlTL: A Simple Erlang Template Language
Have you ever wanted to build the kind of mail-merge program that never crashes, that runs on a scalable fault tolerant cluster, that you can easily scale by adding more boxes, that you can hot-swap its code without taking it offline, that runs on an optimized VM that can handle hundreds of thousands of simultaneous tasks at a time, and that's built with the same technology that powers England's phone network with a long string of nines after the dot?
If you do, you're probably a dirty scumbag spammer, so go to hell :)
But assuming you're not a spammer and/or you want an easy way of embedding small logic snippets in large swaths of Erlang binary data, you will probably enjoy ErlTL: A Simple Erlang Template Language.
ErlTL does not aim to be the most feature-rich template language. It may not have any time soon that feature that you really like in another template language and that makes your web designers oh so happy. (Of course, you're always welcome to implement it yourself and share it with us. If it's useful, I'll add it to the standard distribution). Currently, ErlTL has 4 main objectives:
- Speed. ErlTL compiles template files into BEAM files prior to execution for top-notch performance.
- Simplicity. ErlTL has the smallest number of syntactic elements that are sufficient for it to be useful (at least, useful for me :) ).
- Reusability. ErlTL lets you reuse templates and template fragments, even from different template files.
- Good error reporting. When you write an invalid expression, the ErlTL compiler makes sure you know on which line the problem is.
Let's take a look at an example. Below is a simple template file called song.et (ErlTL files have the '.et' extension by convention).
Now, let's use this template. Fire up the shell and type:
If you didn't mess up, this is the output you'll get:
If this isn't exactly what you were expecting, don't panic. For efficiency, ErlTL doesn't try to concatenate all outputs. If you need to concatenate them, you can do it manually, e.g. with iolist_to_binary/1. However, doing so is often unnecessary when you want to send the result to an IO device such as a socket.
So what's happening here? ErlTL creates a module called 'song', with a function called 'render'. This function takes one parameter called 'Data'. (ErlTL also creates a zero-parameter function that calls the 1 parameter function with 'undefined' as the value for 'Data'.) After you compile the template, you can call these functions from template code snippets as well as from any Erlang module.
The template syntax consists of the following elements:
An Erlang code block is a sequence of Erlang expressions (separated by commas). The result of the expressions is included in the function's output.
Comments are ignored by the compiler
The results of top-level expressions are excluded from the function's output. They are used primary to bind variables to elements of the Data parameter. Top level expressions must go before all standard expressions in the same function.
Function declarations tell the compiler that all the code following the declaration belongs to a new function with the given name. This is useful when you want to reuse a template snippet. Note that all functions are exported, so you can reuse code by calling functions from other templates. Let's look at a simple example, called album.et:
In the shell, type the following:
(Beatles fans, please forgive me for not typing all the song names! I got tired :) ) This will give you the following output:
That's pretty much all these is to ErlTL at the moment. At some point, it may be beneficial to add some iteration syntax, but I'm not planning on doing this in the near future. I hope you find ErlTL useful. As always, please let me know if you have any comments, suggestions or bug reports.
Enjoy!
Note: the current release is in the 0.9 branch in the repository.
If you do, you're probably a dirty scumbag spammer, so go to hell :)
But assuming you're not a spammer and/or you want an easy way of embedding small logic snippets in large swaths of Erlang binary data, you will probably enjoy ErlTL: A Simple Erlang Template Language.
ErlTL does not aim to be the most feature-rich template language. It may not have any time soon that feature that you really like in another template language and that makes your web designers oh so happy. (Of course, you're always welcome to implement it yourself and share it with us. If it's useful, I'll add it to the standard distribution). Currently, ErlTL has 4 main objectives:
- Speed. ErlTL compiles template files into BEAM files prior to execution for top-notch performance.
- Simplicity. ErlTL has the smallest number of syntactic elements that are sufficient for it to be useful (at least, useful for me :) ).
- Reusability. ErlTL lets you reuse templates and template fragments, even from different template files.
- Good error reporting. When you write an invalid expression, the ErlTL compiler makes sure you know on which line the problem is.
Let's take a look at an example. Below is a simple template file called song.et (ErlTL files have the '.et' extension by convention).
<%! This template composes beautiful songs %>
<%? [What, Where, Objects, Action] = Data %>
<% What %> singing in <% Where %>,
Take these <% Objects %> and learn to <% Action %>
Now, let's use this template. Fire up the shell and type:
erltl:compile("/path/to/song.et"),
song:render([<<"Blackbird">>,
<<"the dead of the night">>, <<"broken wings">>,
<<"fly">>]).
If you didn't mess up, this is the output you'll get:
[<<"\n\n">>,
<<"Blackbird">>,
<<" singing in ">>,
<<"the dead of the night">>,
<<",\nTake these ">>,
<<"broken wings">>,
<<" and learn to ">>,
<<"fly">>,
<<"\n">>]
If this isn't exactly what you were expecting, don't panic. For efficiency, ErlTL doesn't try to concatenate all outputs. If you need to concatenate them, you can do it manually, e.g. with iolist_to_binary/1. However, doing so is often unnecessary when you want to send the result to an IO device such as a socket.
So what's happening here? ErlTL creates a module called 'song', with a function called 'render'. This function takes one parameter called 'Data'. (ErlTL also creates a zero-parameter function that calls the 1 parameter function with 'undefined' as the value for 'Data'.) After you compile the template, you can call these functions from template code snippets as well as from any Erlang module.
The template syntax consists of the following elements:
<% [Erlang code block] %>
An Erlang code block is a sequence of Erlang expressions (separated by commas). The result of the expressions is included in the function's output.
<%! [comment] %>
Comments are ignored by the compiler
<%? [top-level expressions] %>
The results of top-level expressions are excluded from the function's output. They are used primary to bind variables to elements of the Data parameter. Top level expressions must go before all standard expressions in the same function.
<%@ [function declaration] %>
Function declarations tell the compiler that all the code following the declaration belongs to a new function with the given name. This is useful when you want to reuse a template snippet. Note that all functions are exported, so you can reuse code by calling functions from other templates. Let's look at a simple example, called album.et:
<%! This template prints an album data in HTML %>
<%? {Title, Artist, Songs} = Data %>
Title: <% Title %>
Artist: <% Artist %>
Songs:
<% [song(Song) || Song <- Songs] %>
<%@ song %>
<%? {Number, Name} = Data %>
<% integer_to_list(Number) %>
<% Name %>
In the shell, type the following:
erltl:compile("/path/to/album.et"),
album:render(
{<<"Abbey Road">>, <<"The Beatles">>,
[{1, <<"Come Together">>},
{2, <<"Something">>},
{3, <<"Maxwell's Silver Hammer">>},
{4, <<"Oh! Darling">>},
{5, <<"Octopus's Garden">>},
{6, <<"I Want You (She's So Heavy)">>}]
}).
(Beatles fans, please forgive me for not typing all the song names! I got tired :) ) This will give you the following output:
[<<"\n\n\n\nTitle: ">>,
<<"Abbey Road">>,
<<"
\nArtist: ">>,
<<"Beatles">>,
<<"
\nSongs:
\n\n">>,
[[<<"\n\n\n ">>,
"1",
<<" \n ">>,
<<"Come Together">>,
<<" \n \n">>],
[<<"\n\n\n ">>,
"2",
<<" \n ">>,
<<"Something">>,
<<" \n \n">>],
[<<"\n\n\n ">>,
"3",
<<" \n ">>,
<<"Maxwell's Silver Hammer">>,
<<" \n \n">>],
[<<"\n\n\n ">>,
"4",
<<" \n ">>,
<<"Oh! Darling">>,
<<" \n \n">>],
[<<"\n\n\n ">>,
"5",
<<" \n ">>,
<<"Octopus's Garden">>,
<<" \n \n">>],
[<<"\n\n\n ">>,
"6",
<<" \n ">>,
<<"I Want You (She's So Heavy)">>,
<<" \n \n">>]],
<<"\n
\n\n\n\n">>]
That's pretty much all these is to ErlTL at the moment. At some point, it may be beneficial to add some iteration syntax, but I'm not planning on doing this in the near future. I hope you find ErlTL useful. As always, please let me know if you have any comments, suggestions or bug reports.
Enjoy!
Note: the current release is in the 0.9 branch in the repository.
Wednesday, October 11, 2006
Recless: A Type Inferring Parse Transform for Erlang (Experimental)
Warning: Recless is highly experimental, and it's not yet finished. Use it at your own risk!!!
My cell phone's favorite feature is the auto-complete mode. With auto-complete, my cell phone guesses what words I'm trying to type based on which words in its database are most likely to match the combination of digits I have entered. For instance, if I wanted to type the word 'hello', I could type '43556' instead of '4433555555666'.
The main drawback is that my cell phone has a limited words database, so when I want to type a word that's not in the database, I have to press some extra keys to switch from auto-complete to manual mode and back again, which is somewhat annoying.
(This happens more often than you would think: the database doesn't hold a single English curse word -- not even 'damn'! WTF :) )
Last week, I had the idea to implement a similar feature for Erlang. In case you haven't used Erlang and you're horrified about the possible implications of the previous statement, don't worry -- Erlang doesn't limit you to coding using only your keyboard's number pad :) However, Erlang does have some idioms that could benefit from some trimming IMO: record getters and setters.
Let's take a detour into a discussion of Erlang's records. Erlang is a dynamically typed functional language. It has no notion of classes and objects. If you want to group a few data elements together, you can put them in a list or in a tuple. To store a fixed number of elements, you use a tuple. For a variable number of elements, you use a (linked) list.
When you use tuples as containers, you have to know the position of each field in the tuple in order to access or change the value of the field. This works well in many cases, and it makes pattern-matching very natural, but it doesn't work well in all cases. Sometimes you want to give a name to a data element and access it using its name, not its position. That's where records come in.
Records basically provide syntactic sugar for tuple creation as well as element access and manipulation. They let you give names to fields, and they resolve the positions for you in compile time. For example, let's say we have defined the following records:
To create a tuple of "type" address and bind it to the variable named Address, you could write
This would bind Address the value {address, "700 Boylston", "Boston", "USA"}. (The country field demonstrates how to set default values to record fields).
To get the street from an address, you have 3 options:
Update (10/12/2006): It has been brought to my attention that there's another, perferred way of writing the above logic (thanks, Bengt):
Changing a record's fields requires additional syntax. Here's an example:
Record values can be nested in other records. Example:
Some people find the standard field access and manipulation syntax somewhat less than beautiful, and I sympathize with them. In almost all OO languages, using properties of an object it as simple as writing 'person.city'. This syntax is obviously more lightweight, but it also comes at the cost of maintaining type data in runtime and/or embracing full static typing. (This is another reminder that no language is perfect -- not even Erlang! :) Actually, many people would say Lisp is perfect... but I digress).
The Erlang record syntax gets even more cumbersome when working with nested records. Let's say we want to get the city of the owner of Project. This is how we go about it using the record syntax:
If you think that's an eyesore, consider *changing* the value of the city:
Yes, I know. Ugly. That's why I created Recless.
Recless is a parse transform that uses a type inference algorithm to figure out what kinds of records your variables are holding, and then lets you write much less code to work with their elements. For example, with Recless, the above two examples could be written as
and
All you have to do to enable this syntax is to put recless.erl in your source directory and add the following declaration at the top of your source file:
The holy grail for Recless is to Just Work. There is, however, one main restriction in Recless's type inference algorithm: function parameters must indicate their record types for type inference to work on them. For instance, this won't work:
Instead, you must write this:
Recless is already pretty good at figuring out the types of your variables, but there are many cases that it doesn't handle yet. It also probably has some bugs. The reason I'm releasing it now is that when I got the idea to make Recless, I seriously underestimated how hard it would be to make it. I thought it would take 2, at most 3 days, but I've already spent more time than that, and I'm only 75% or so done. Before I dig myself any deeper, I wanted to get some feedback from the Erlang community. If many people want Recless, and everybody agrees that Recless can't mess up any code that's written in standard Erlang, I'll devote the extra time to finishing it. Otherwise, I'll go back to other projects and maybe finish it later when I have some more time.
You can get the source for Recless here: http://code.google.com/p/recless. It also includes a test file that demonstrates what Recless can do at the moment.
Note: Although Recless does a good amount of type inference, it does not attempt to catch type errors. Dialyzer already does a fantastic job at that. All Recless tries to do at the moment is simplify record access and manipulation syntax. If Recless fails to infer the type of an expression such as "Person.name", it crashes with a type_inference error (this will be improved up if/when Recless grows up).
I'll appreciate any feedback!
My cell phone's favorite feature is the auto-complete mode. With auto-complete, my cell phone guesses what words I'm trying to type based on which words in its database are most likely to match the combination of digits I have entered. For instance, if I wanted to type the word 'hello', I could type '43556' instead of '4433555555666'.
The main drawback is that my cell phone has a limited words database, so when I want to type a word that's not in the database, I have to press some extra keys to switch from auto-complete to manual mode and back again, which is somewhat annoying.
(This happens more often than you would think: the database doesn't hold a single English curse word -- not even 'damn'! WTF :) )
Last week, I had the idea to implement a similar feature for Erlang. In case you haven't used Erlang and you're horrified about the possible implications of the previous statement, don't worry -- Erlang doesn't limit you to coding using only your keyboard's number pad :) However, Erlang does have some idioms that could benefit from some trimming IMO: record getters and setters.
Let's take a detour into a discussion of Erlang's records. Erlang is a dynamically typed functional language. It has no notion of classes and objects. If you want to group a few data elements together, you can put them in a list or in a tuple. To store a fixed number of elements, you use a tuple. For a variable number of elements, you use a (linked) list.
When you use tuples as containers, you have to know the position of each field in the tuple in order to access or change the value of the field. This works well in many cases, and it makes pattern-matching very natural, but it doesn't work well in all cases. Sometimes you want to give a name to a data element and access it using its name, not its position. That's where records come in.
Records basically provide syntactic sugar for tuple creation as well as element access and manipulation. They let you give names to fields, and they resolve the positions for you in compile time. For example, let's say we have defined the following records:
-record(address, {street, city, country = "USA"}).
-record(person, {name, address = #address{}}).
-record(project, {name, owner = #person{}}).
To create a tuple of "type" address and bind it to the variable named Address, you could write
Address = #address{street = "700 Boylston", city = "Boston"},
This would bind Address the value {address, "700 Boylston", "Boston", "USA"}. (The country field demonstrates how to set default values to record fields).
To get the street from an address, you have 3 options:
Street = Address#address.street,
{_,Street,_,_} = Address,
Street = element(2, Address)
Update (10/12/2006): It has been brought to my attention that there's another, perferred way of writing the above logic (thanks, Bengt):
#address{street=Street} = Address,
Changing a record's fields requires additional syntax. Here's an example:
NewAddress = Address#address{street =
"77 Massachusetts Avenue", city="Cambridge"}
Record values can be nested in other records. Example:
Project =
#project{name = "MyProject",
owner = #person{name = "Bob",
address = #address{city = "Miami" }}}
Some people find the standard field access and manipulation syntax somewhat less than beautiful, and I sympathize with them. In almost all OO languages, using properties of an object it as simple as writing 'person.city'. This syntax is obviously more lightweight, but it also comes at the cost of maintaining type data in runtime and/or embracing full static typing. (This is another reminder that no language is perfect -- not even Erlang! :) Actually, many people would say Lisp is perfect... but I digress).
The Erlang record syntax gets even more cumbersome when working with nested records. Let's say we want to get the city of the owner of Project. This is how we go about it using the record syntax:
City = ((Project#project.owner)
#person.address)#address.city
If you think that's an eyesore, consider *changing* the value of the city:
NewProject =
Project#project{owner =
(Project#project.owner)#person{address =
((Project#project.owner)
#person.address)#address{city = "Boston"}}}.
Yes, I know. Ugly. That's why I created Recless.
Recless is a parse transform that uses a type inference algorithm to figure out what kinds of records your variables are holding, and then lets you write much less code to work with their elements. For example, with Recless, the above two examples could be written as
City = Project.owner.city.
and
NewProject = Project.owner.address.city = "Boston".
All you have to do to enable this syntax is to put recless.erl in your source directory and add the following declaration at the top of your source file:
-compile({parse_transform, recless}).
The holy grail for Recless is to Just Work. There is, however, one main restriction in Recless's type inference algorithm: function parameters must indicate their record types for type inference to work on them. For instance, this won't work:
get_name(Person) -> Person.name.
Instead, you must write this:
get_name(Person = #person{}) -> Person.name.
Recless is already pretty good at figuring out the types of your variables, but there are many cases that it doesn't handle yet. It also probably has some bugs. The reason I'm releasing it now is that when I got the idea to make Recless, I seriously underestimated how hard it would be to make it. I thought it would take 2, at most 3 days, but I've already spent more time than that, and I'm only 75% or so done. Before I dig myself any deeper, I wanted to get some feedback from the Erlang community. If many people want Recless, and everybody agrees that Recless can't mess up any code that's written in standard Erlang, I'll devote the extra time to finishing it. Otherwise, I'll go back to other projects and maybe finish it later when I have some more time.
You can get the source for Recless here: http://code.google.com/p/recless. It also includes a test file that demonstrates what Recless can do at the moment.
Note: Although Recless does a good amount of type inference, it does not attempt to catch type errors. Dialyzer already does a fantastic job at that. All Recless tries to do at the moment is simplify record access and manipulation syntax. If Recless fails to infer the type of an expression such as "Person.name", it crashes with a type_inference error (this will be improved up if/when Recless grows up).
I'll appreciate any feedback!
Tuesday, October 10, 2006
Going to the Erlang Conference
I'm not exactly enjoying what one would call a "positive" cash flow these days, but I decided to dig into my hard earned budget anyway and spend a chunk of it on a trip to Sweden for the 12th annual Erlang conference.
Here's my dilemma: I want to take this opportunity to make a 2 week backpacking trip in Europe. I want to see Sweden, but I'm afraid it will be too cold to enjoy in the winter. I can either stay in Sweden after the conference, or hop on a plane to France or Spain (I *really* want to visit Barcelona).
I'd appreciate it if anyone could give me some tips on what I should do.
To save money, and also to stay true to the spirit of backpacking, I'll be staying in hostels, which means I probably won't bring my MacBook. I hope that spending 2 weeks without a computer won't result in serious withdrawal symptoms.
Here's my dilemma: I want to take this opportunity to make a 2 week backpacking trip in Europe. I want to see Sweden, but I'm afraid it will be too cold to enjoy in the winter. I can either stay in Sweden after the conference, or hop on a plane to France or Spain (I *really* want to visit Barcelona).
I'd appreciate it if anyone could give me some tips on what I should do.
To save money, and also to stay true to the spirit of backpacking, I'll be staying in hostels, which means I probably won't bring my MacBook. I hope that spending 2 weeks without a computer won't result in serious withdrawal symptoms.
Monday, October 09, 2006
Blogging About Erlang
Wow. I read today some of my old articles and I must say I wish I had spent some more time refining them before I hit that 'publish' button. They're not all bad... Even the more enthusiastic ones are definitely amusing at least for a personal blog of a hacker discovering a wonderful new toy. However, now that my blog became more popular than it had been when I wrote most of them I feel that it calls for a more sober writing style. I have learned that many of my readers are quite hype-weary from J2EE and then Ruby being sold to them as the Next Great Thing, and the last thing I would want is for them to feel the same about Erlang.
ERLANG SUCKS. DON'T USE IT!!! STICK WITH RUBY!!!
There. Now nobody can accuse me of hype instigation :)
Then again, maybe my initial learning towards a controversial writing style has drawn more people's attention to my blog, and I'll do anything to serve The Cause... Just kidding... :)
I think most reddit readers have gotten by now what makes Erlang different. From now on, I will let the language sell itself, and focus my writing about the topic about which I care the most: the code.
(I also promise I will never write an article about Agile development. I don't even know what it really means!!! I guess my ignorance makes my coding Sluggish :) )
Believe it or not, I don't care *that* much if Erlang becomes mainstream. It would be great if many people used it, if for no other reason than the satisfaction they would experience by using a real functional language that makes concurrent programming a joy. The main reason I started blogging about Erlang is that I recognized it would be a great tool writing certain apps, and the last thing I wanted was when people would me how I built something and I would say, "I used Erlang," they would ask "ErlWhat???"
Despite my nitpicking, I'm pretty happy with the way things have played out so far. From other articles I'm reading these days, I get the impression that now many more people understand and respect Erlang. If nothing else, I have a lot of respect for the people who created Erlang because they have solved some of the hardest problems in creating tools for building scalable, fault-tolerant, distributed systems -- an area that feels mostly abandoned by most programming languages. They also gave their creation to us for free. I wouldn't be as good a programmer if I hadn't spent the time using Erlang and learning what makes it special.
In the spirit of American capitalism, I should try to make a buck from my blog. Therefore, expect my new book to hit the stores in two months: Sluggish Development With Erlang for the Hype-Averse, Battle-Scarred Programmer :)
ERLANG SUCKS. DON'T USE IT!!! STICK WITH RUBY!!!
There. Now nobody can accuse me of hype instigation :)
Then again, maybe my initial learning towards a controversial writing style has drawn more people's attention to my blog, and I'll do anything to serve The Cause... Just kidding... :)
I think most reddit readers have gotten by now what makes Erlang different. From now on, I will let the language sell itself, and focus my writing about the topic about which I care the most: the code.
(I also promise I will never write an article about Agile development. I don't even know what it really means!!! I guess my ignorance makes my coding Sluggish :) )
Believe it or not, I don't care *that* much if Erlang becomes mainstream. It would be great if many people used it, if for no other reason than the satisfaction they would experience by using a real functional language that makes concurrent programming a joy. The main reason I started blogging about Erlang is that I recognized it would be a great tool writing certain apps, and the last thing I wanted was when people would me how I built something and I would say, "I used Erlang," they would ask "ErlWhat???"
Despite my nitpicking, I'm pretty happy with the way things have played out so far. From other articles I'm reading these days, I get the impression that now many more people understand and respect Erlang. If nothing else, I have a lot of respect for the people who created Erlang because they have solved some of the hardest problems in creating tools for building scalable, fault-tolerant, distributed systems -- an area that feels mostly abandoned by most programming languages. They also gave their creation to us for free. I wouldn't be as good a programmer if I hadn't spent the time using Erlang and learning what makes it special.
In the spirit of American capitalism, I should try to make a buck from my blog. Therefore, expect my new book to hit the stores in two months: Sluggish Development With Erlang for the Hype-Averse, Battle-Scarred Programmer :)
Wednesday, October 04, 2006
Today's Innovation Prize Goes To...
the City of Boston -- for its solar-powered trash compactors!

I must praise this compactor for its fault tolerant design: even if the power grid fails, it keeps compacting away. Very Erlangy :)
(Alas, if the sun fails, it is in trouble -- but then we'd have bigger problems to worry about :) )
I must praise this compactor for its fault tolerant design: even if the power grid fails, it keeps compacting away. Very Erlangy :)
(Alas, if the sun fails, it is in trouble -- but then we'd have bigger problems to worry about :) )
Tuesday, October 03, 2006
Going to the Paul Graham Talk
After weeks of bombarding me with tedious Erlang hype, reddit has finally given me a useful link: Paul Graham (whom I've been accused of over-quoting :) ), will be speaking tomorrow at MIT. (For literal minded people -- I didn't mean the first part of that sentence seriously :) ) It's a free talk that's open to the public.
Is anybody who reads this blog going?
Saturday, September 30, 2006
ErlyDB 0.7
In the past couple of weeks, I've been hacking away at ErlyDB and the libraries it uses (the Revamped MySQL driver, ErlSQL and Smerl). I added a bunch of features and optimizations and also refactored and/or rewrote most of the original ErlyDB code until I felt the picture looked good.
The last release was v0.1, but I decided to name this release v0.7 because ErlyDB getting pretty close to 1.0 quality. Plus, I just like the number 0.7 :)
Here are the main new features:
Transactions
Each generated module has the function transaction/1, which lets you execute a group of statements in a transaction against the module's driver. Here's an example:
person:transaction(
fun() ->
P = person:new("Menahem"),
P1 = person:save(P),
city:add_person(TelAviv, P1)
end).
Transactions are automatically rolled back if the function throws an error or crashes. For example, this function
person:transaction(
fun() ->
person:delete(P1),
exit(just_kidding)
end).
would cause the delete statement to be rolled back.
Note: all auto-generated CRUD operations are executed in transactions, so you can set your database's auto-commit option to 'false' and nothing will break.
Protection against SQL injection attacks
ErlyDB uses ErlSQL under the hood to automatically quote all string and binary values in SQL expressions. All functions that let the user define a Where condition expect an ErlSQL expression by default. Here are some examples:
person:find({name, '=', "Joe"}).
person:find(
{{name,'=',"Joe"}, 'or', {'not', {age, '<', 26}}}).
You can also use ErlSQL expressions for LIMIT and ORDER BY clauses, such as
person:find({name, like, "Joe%"},
[{order_by, [{age, desc}, country]},
{limit, 3, 4}]).
If you want to use string and/or binary expressions, you can define the {allow_unsafe_statements, true} option when calling erlydb:code_gen/3. This will tell ErlyDB to accept statements such as
person:find("name = 'Joe'").
and
person:find("name LIKE 'Joe%'", "LIMIT 17").
However, this usage is discouraged because it makes you more vulnerable to SQL injection attacks. If you turn this feature on, make sure to escape all your strings using erlsql:encode/1.
Hooks
You can implement in your modules the following functions, which ErlyDB will use as hooks for different operations:
after_fetch/1
before_save/1
after_save/1
before_delete/1
after_delete/1
Fine-grained control on field visibility
By implementing the fields/0 function in your modules, you can specify exactly which database fields ErlyDB will use for the module. For example, if you have the function
fields() -> [name, age, country].
in the module 'person', ErlyDB will only use those fields even if the database table has additional fields (the 'id' field is always assumed to be the primary key).
User-defined table assignment
You can implement the table/0 function to indicate which table ErlyDB should use as the database table for your module. For example, the function
table() -> person.
in the module 'artist' would tell ErlyDB to use the 'person' table in all SQL statements for the module 'artist'.
Multiple modules per table
You can implement the type_field/0 function to indicate which column in the database table holds the module type for each record. In combination with the table/0 function, this lets you store records for multiple modules in a single table. By implementing the fields/0 function, you can also control which fields are exposed for each module.
For example, suppose you have the table 'person' defined as
CREATE TABLE person (
id integer auto_increment primary key,
type char(10),
name varchar(30),
age integer,
country varchar(20),
office integer,
department varchar(30),
genre varchar(30),
instrument varchar(30),
created_on timestamp,
index(type)
)
You can create 3 modules for accessing this table as follows:
person.erl
-module(person).
-export([fields/0, type_field/0]).
fields() -> [name, age, country].
type_field() -> type.
employee.erl
-module(employee).
-export([table/0, fields/0, type_field/0]).
table() -> person.
fields() -> person:fields() ++ [office, department].
type_field() -> type.
musician.erl
-module(musician).
-export([table/0, fields/0, type_field/0]).
table() -> person.
fields() -> person:fields() ++ [genre, instrument].
type_field() -> type.
The created_on field will not be exposed to any of the modules.
Note: The fields/0 function isn't limited to defining supersets. You can define any relation you want, as long is it's expressible in Erlang :)
More auto-generated functions
In addition to the find(Where, Extras) and find_id(Id) functions, ErlyDB now generates find_max(Max, Where, Extras) for getting at most Max records, and find_range(First, Max, Where, Extras) for getting at most Max records starting from offset First. Each function has 4 variants, e.g.
find()
find(Where)
find_with(Extras)
find(Where, Extras)
Functions for finding related records also have such variants. Examples:
developer:projects(D)
developer:projects(D, Where)
developer:projects_with(D, Extras)
developer:projects(D, Where, Extras)
developer:projects_first(D)
developer:projects_first(D, Where)
developer:projects_first_with(D, Extras)
developer:projects_first(D, Where, Extras)
developer:projects_max(D, Max),
developer:projects_max(D, Max, Where),
developer:projects_max_with(D, Max, Extras)
developer:projects_max(D, Max, Where, Extras)
developer:projects_range(D, First, Max),
developer:projects_range(D, First, Max, Where),
developer:projects_range_with(D, First, Max, Extras)
developer:projects_range(D, First, Max, Where, Extras)
Aggregate functions
ErlyDB generates functions for getting aggregate data about records from a module. The functions currently supported are 'count', 'max', 'min', 'avg', 'sum' and 'stddev' (it's easy to add more functions to this list by changing aggregate_functions/0 in erlydb.erl). For example, you can make calls such as
person:max(age).
employee:count('distinct name').
season:avg(temperature).
city:sum(population, {country,'=',"USA"}).
to get aggregate values from the database. The 'count' function has a special version that takes no arguments.
person:count().
is equivalent to
person:count('*').
In addition, ErlyDB lets you query aggregate data about related records (both in one_to_many and many_to_many relations). Examples:
developer:sum_of_projects(Joe, language).
apple:avg_of_oranges(MyApple, color,
{{state,'=',"ripe"},'and',{size, '>', 3}}).
The special form of 'count' also exists for related records:
language:count_of_developers(Erlang).
Better error handling
In the last version of ErlyDB, functions returned {ok, Result} or {error, Err}. In version 0.7, I changed it so functions return Result or they crash by calling exit(Err). This makes it easier to execute a group of statements and let the enclosing function trap all the errors (it also follows the Mnesia API more closely).
Multiple drivers, multiple databases in one session
The last version of ErlyDB supported only one driver per session. In version 0.7, each module can have a different driver. In addition, each module can have a list of driver options defined when calling erlydb:code_gen/3. All generated functions pass these options to the driver. For example, the MySQL driver accepts the {pool_id, Val} option, which defines against which connection pool ErlyDB should execute SQL statements. This allows you to work with multiple MySQL databases in one ErlyDB session.
Efficient SQL generation
In the last version, ErlyDB created SQL statements by string concatenation. In version 0.7, ErlyDB uses ErlSQL to generate statements as iolists of binaries, which are more efficient than strings because they consume less memory.
Many internal improvements
I rewrote or refactored most of the code from the alpha version. I also optimized the code generation process so it's much faster now.
That's it :)
You can get the distribution from branches/v0.7 in the subversion repository.
Note: ErlyDB requires the Revamped MySQL Driver v0.9.5 or above, which you can get from the Subversion repository under branches/v0.9.5. This driver is based on the original MySQL driver from the YXA project with a improvements I made such as support of transactions, prepared statements, binary queries and more efficient connection pooling. Once the changes I made to this driver are integrated back into the YXA source repository, the Revamped driver will no longer be supported. This is to ensure that the Erlang community doesn't have to deal with multiple forks of the same driver.
Please let me know if you find any bugs or if you have any suggestions.
Monday, September 25, 2006
Mnesia? MySQL? It's The Same Transaction!
I have a confession: I didn't like my last attempt at adding transaction support to the Revamped MySQL Driver. Don't get me wrong -- it's better to have some transaction support in the driver than none, but the approach I took had a couple of shortcomings. One was minor and one major.
The minor shortcoming was that the transaction handling added a non-trivial level of complexity to the API due to its introduction of a few new functions such as new_transaction(), add_statement(), add_execute() and commit(). This made the MySQL transaction API much less elegant than the Mnesia transaction API, which, in its simplest form, boils down to a single function -- mnesia:transaction/1.
As an example, compare
T = mysql:new_transaction(pool_id),
T1 = mysql:add_query(T,
<<"INSERT INTO person(name) VALUES ('bob')">>),
Res = mysql:commit(T1).
to
mnesia:transaction(fun() -> mnesia:write(Bob) end).
Even ignoring the ugliness of the SQL statement, it's easy to see that the Mnesia example is much clearer.
My attempt at simplifying the MySQL transaction handling by making it possible to write the above example as
mysql:transaction(pool_id, fun(T) ->
add_query(T,
<<"INSERT INTO person(name) VALUES ('bob')">>)
end)
was in improvement, but it still added more complexity to the driver's API than the Mnesia's single transaction function.
Putting aesthetic concerns aside for a second, having a transaction API that's different from Mnesia's would make my life hard when implementing different ErlyDB drivers that must conform to the same transaction specifications. Having a consistent approach to transactions in all drivers was quite important for ErlyDB.
The bigger shortcoming with the original transaction interface in the MySQL driver was that although it was possible to execute a sequence of INSERT, UPDATE and DELETE statements in a transaction, it was impossible to execute SELECT statements in a transaction and actually do something with the results. For example, it was impossible to do the equivalent of
mysql:fetch(p1, <<"BEGIN">>),
mysql:fetch(p1,
<<"INSERT INTO person(name) VALUES ('bob')">>),
Res = mysql:fetch(p1,
<<"SELECT last_insert_id()">>),
[[Id]] = mysql:get_result_rows(Res),
mysql:fetch(p1,
["UPDATE person SET name='Jane' WHERE id=",
integer_to_list(Id)]),
mysql:fetch(p1, <<"COMMIT">>).
Even worse, if you had more than one connection in the connection pool, there was no way at all to implement the above transaction because the connection pooling algorithm would execute each statement in a different connection!
Ouch.
I basically ran into 2 problems: in Erlang, functions are stateless. There was no way for mysql:fetch to know that it's part of a transaction unless it was given a parameter that would inform it of this fact. (This parameter could either be a transaction record, as in the original approach, or a continuation, letting the user implement transactions in continuation passing style.) In addition, the transaction function executed in the client process, but each SQL statement was executed in the process of a connection chosen by the dispatcher. The only way to execute a group of statements in one connection is to send them to the dispatcher in a batch.
The first problem caused the API complexity; the second problem made using results from SELECT statements inside a transaction impossible.
Fortunately, I was able to find work-arounds to both problems.
To tackle the first issue, I dug deep into my memory of obscure Erlang documentation I had read. In the Advanced Topics section of the Erlang course is a short section on the process dictionary. In Erlang, each process has a mutable data structure called the process dictionary. The process dictionary allows you to 'cheat' by storing in it values and later retrieving them in other functions without passing those values as explicit parameters. This feature is generally discouraged because it makes your code less readable and it potentially introduces obscure bugs. (It's interesting how in most programming languages, mutable data is a fact of life, whereas functional languages such as Erlang and Haskell teach you to avoid it as much as possible :) ). I have never used the process dictionary before, and I will do my best to refrain from using it again, but for this specific feature, it was very useful.
Detour: It is actually possible to emulate the process dictionary in a "clean" way using an Erlang process that maintains state for all other processes. To get and set the state for the current process, you would make calls such as
State = gen_server:call(state_server,
{get_state, self()}).
and
gen_server:cast(state_server,
{set_state, self(), State})
(gen_server:call is blocking and get_server:cast is non-blocking).
The main disadvantages with this approach is that it involves a higher overhead due to message passing and that the state server needs to monitor other processes using erlang:monitor in order to garbage-collect state data belonging to processes that have died or crashed.
Back to the MySQL driver: With the process dictionary, mysql:fetch and mysql:execute could know that they were called inside a transaction, which made it possible to remove the mysql:add_query and mysql:add_execute functions. However, I still faced the problem that each call to mysql:fetch and mysql:execute would go to a different connection because of the connection pooling mechanism.
Thankfully, Erlang let me solve this problem quite elegantly: send the transaction function to the connection's process via the dispatcher, execute the function in the connection's process, and then send the result of the function to the calling process!
(For veteran Erlangers, this is probably far from groundbreaking, but for me, the notion of sending a function to different process that would execute it and send back the result is pretty cool. This is another small way in which Erlang has changed the way I think about programming.)
This is the solution I implemented in the MySQL driver. When you call mysql:transaction(ConnPool, Fun), the Fun parameter is sent to the dispatcher, which picks the next connection from the connection pool and then sends the Fun to the connection's process. The connection process puts a flag in the process dictionary marking the existence of a transaction context, and then executes the Fun. Calls to mysql:fetch and mysql:execute inside the Fun pick up the transaction context, and instead of sending their SQL statements to the dispatcher, they call mysql_conn functions directly. This ensures that all statements in a transaction are executed in the same connection.
With this new approach, the MySQL driver now lets you write transaction handling code in the style of the Mnesia API. The new way of writing the above example is:
mysql:prepare(insert_developer,
<<"INSERT INTO developer(name) VALUES (?)">>),
mysql:transaction(conn_pool,
fun() ->
mysql:execute(insert_developer, ["Bob"]),
{data, Res} =
mysql:fetch(<<"SELECT last_insert_id()">>),
[[Id]] = mysql:get_result_rows(Res),
mysql:fetch(
[<<"UPDATE developer SET name='Jane' WHERE id=">>,
integer_to_list(Id)])
end).
Two notes about this example:
- The PoolId parameter is no longer necessary in calls to mysql:fetch and mysql:execute when they are called inside a transaction. For consistency, you can keep the parameter in the calls -- it'll just be ignored.
- The last call to mysql:fetch demonstrates the use of iolists, which are more efficient than string concatenation in certain cases, such as when you're sending the result to a socket.
I made another change to the MySQL driver besides the transaction API change: inspired by Joe Armstrong's last article about transactional memory, I added versioning to prepared statements. In the last version, when a prepared statement changed, the dispatcher would scan all connections and the ones that have marked it as prepared would be updated. This solution is fine as long as there aren't too many database connections and the set of prepared statements is stable, but it doesn't scale too well.
In the latest version of the driver, I made it so when mysql:execute sends a request to the dispatcher, the dispatcher checks what the latest version of the statement is in its memory and then forwards to the request to execute the prepared statement with the given version to a connection from the connection pool. If the connection hasn't prepared the statement or if the prepared version of the statement in the connection is lower than the one in the dispatcher's request, the connection would request the latest version of the statement from the dispatcher. This ensures that all connections execute the latest version of each statement while keeping communications to a minimum.
(Things actually get more complicated when a call to mysql:execute is made in a transaction, but I'll spare you such messy details :) )
I put the new version for the driver in branches/v0.9. The old version is in branches/v0.8. Please get the latest version, give it a test drive and let me know if you find any problems (I tested it myself and it looks pretty stable).
Now that the MySQL driver looks solid, I can finally go back to ErlyDB :)
Update: I forgot to mention that transactions are automatically rolled back if the Fun returns or throws {error, Err}. For instance,
mysql:transaction(conn_pool1,
fun() ->
mysql:fetch(<<"DELETE FROM customer">>,
throw({error, just_kidding})
end).
would have no impact on the data because cause the transaction will be rolled back.
Saturday, September 23, 2006
Revamped MySQL Driver Update
I made a number of changes to the Revamped MySQL Driver code. These are the major items:
- I rewrote much of the prepared statement handling logic. I improved it by adding versioning to prepared statements. I also pushed much of the logic to mysql_conn.erl.
- I simplified the transaction API in the MySQL driver to make it similar to the Mnesia transaction API. I will write a more complete article describing the reasoning as well as how to use the new API tomorrow or the day after. For now, you can read the documentation in the code or look at the test/mysql_test.erl.
The new code is in trunk. The old code is in braches/v0.8.
More details are coming.
Tuesday, September 19, 2006
New ErlSQL Feature: Lisp-style Operator Expansion
When you first write a library, you really don't know how useful it can be. You often discover new ways of enhancing it and making it more powerful only when you start using it. This has been the case with almost every library I wrote: Smerl, ErlyDB, and now ErlSQL.
While I was using ErlSQL to hack ErlyDB's internals, I realized what a pain it is to use the SQL way of writing repeated expressions that use the same binary operator, e.g. {{{a,'=',b}, 'and', {c,'=',d}}, 'and', {e,'=',f}}. Lisp handles such situations much more elegantly than SQL (I know, it's hard to believe that anything could be more elegant than SQL, but what do you know :) ). In Lisp, you would write (and (= a b) (= c d) (= e f)), which spares you having to write the 'AND' operator for each new element in the list.
(Please forgive me if I made any egregious Lisp syntax errors in this example. I haven't touched Lisp since college and my knowledge of it is very rusty :) )
The Lisp way is often much more concise than the SQL way, so I implemented a Lisp-style operator expansion feature in ErlSQL.
Here are a few examples of how to use this feature:
{select,'*',{from,foo},
{where,{a,'=',{'+',[1,2,3]}}}} ->
"SELECT * FROM foo WHERE (a = 1 + 2 + 3)"
{select,'*',{from,foo}
{where,{'=',[{'+',[a,b,c]},{'+',[d,e,f]}]}}} ->
"SELECT * FROM foo WHERE a + b + c = d + e + f"
{select,'*',{from,foo},
{where,
{'and',[{a,'=',b},{c,'=',d},{e,'=',f}]}}} ->
"SELECT * FROM foo WHERE (a = b) AND (c = d) AND (e = f)"
Any expression which is a tuple where the first item is an operator and the second item is a list will be expanded by ErlSQL in a similar fashion.
Saturday, September 16, 2006
Introducing ErlSQL: Easy Expression and Generation of SQL Statements in Erlang
A couple of days ago, I started refactoring some of the code generating SQL statements in ErlyDB. My intention was to modularlize the SQL generation in ErlyDB to make it more flexible and reusable. As I added more and more functions, I suddently found myself with a new domain specific embedded language for expressing SQL statements in Erlang on my hands :) I named this language ErlSQL (ESQL in short).
I created small library for generating literal SQL statements from ESQL expressions. Given that this capability can be useful outside of ErlyDB (for instance, if you are using the Revamped MySQL driver or the Postgres driver from Jungerl directly), I decided to create a new project for this library. ErlSQL now lives at http://code.google.com/p/erlsql.
ErlSQL's main benefits are:
- Easy dynamic generation of SQL queries from Erlang for application developers.
- Prevention of most, if not all, SQL injection attacks by assuring that all string values are properly escaped.
- Integration with higher level libraries such as ErlyDB
ErlSQL covers a large subset of the SQL language and its extensions, including most CREATE, UPDATE, DELETE and SELECT queries. ESQL supports field and table aliases ("foo AS bar"), complex WHERE expressions, ORDER BY and LIMIT clauses, nested queries, function calls, unions, aggregate expressions (using GROUP BY and HAVING clauses), and more.
ErlSQL will gain more capabilities over time. If it's missing a feature you need urgently, it should be fairly straightforward for you to add it youself.
erlsql.erl only has 2 exported functions: sql/1 and sql/2. sql/1 takes an ESQL expression and returns an iolist (a tree of strings and binaries that you can send directly to a socket). sql/2 takes an additional boolean paramemter indicating if the result should be converted to a single binary (via iolist_to_binary/1) or not.
Here are some examples of ESQL expressions and their corresponding SQL queries:
{insert,project,[{foo,5},{baz,"bob"}]} ->
"INSERT INTO project(foo,baz) VALUES (5,'bob')"
{insert,project,[foo,bar,baz],[[a,b,c],[d,e,f]]} ->
"INSERT INTO project(foo,bar,baz) VALUES
('a','b','c'),('d','e','f')"
{insert,project,[foo,bar,baz],[{a,b,c},{d,e,f}]} ->
"INSERT INTO project(foo,bar,baz) VALUES
('a','b','c'),('d','e','f')"
{update,project,[{foo,5},{bar,6},{baz,"hello"}]} ->
"UPDATE project SET foo=5,bar=6,baz='hello'"
{update,project,[{started_on,{2000,21,3}}],{name,like,"blob"}} ->
"UPDATE project SET started_on='2000213'
WHERE (name LIKE 'blob')"
{delete,project} ->
"DELETE FROM project"
{delete,project,{a,'=',5}} ->
"DELETE FROM project WHERE (a = 5)"
{delete,developer,{'not',{{name,like,"%Paul%"},
'or',{name,like,"%Gerber%"}}}} ->
"DELETE FROM developer
WHERE NOT ((name LIKE '%Paul%') OR (name LIKE '%Gerber%'))"
{select,["foo"]} ->
"SELECT 'foo'"
{select,["foo","bar"]} ->
"SELECT 'foo','bar'"
{select,{1,'+',1}} ->
"SELECT (1 + 1)"
{select,{foo,as,bar},{from,{baz,as,blub}}} ->
"SELECT foo AS bar FROM baz AS blub"
{select,name,{from,developer},
{where,{country,'=',"quoted ' \" string"}}} ->
"SELECT name FROM developer
WHERE (country = 'quoted \\' \\\" string')"
{select,[{{p,name},as,name},{{p,age},as,age},{project,'*'}],
{from,[{person,as,p},project]}} ->
"SELECT p.name AS name,p.age AS age,project.*
FROM person AS p,project"
{select,{call,count,name},{from,developer}} ->
"SELECT count(name) FROM developer"
{{select,name,{from,person}},
union,
{select,name,{from,project}}} ->
"(SELECT name FROM person) UNION "
"(SELECT name FROM project)"
{select,distinct,name,{from,person},{limit,5}} ->
"SELECT DISTINCT name FROM person LIMIT 5"
{select,[name,age],{from,person},{order_by,[{name,desc},age]}} ->
"SELECT name,age FROM person ORDER BY name DESC,age"
{select,[{call,count,name},age],{from,developer},{group_by,age}} ->
"SELECT count(name),age FROM developer GROUP BY age"
{select,[{call,count,name},age,country],
{from,developer},
{group_by,[age,country],having,{age,'>',20}}} ->
"SELECT count(name),age,country
FROM developer GROUP BY age,country HAVING (age > 20)"
{select,'*',{from,developer},{where,{name,in,["Paul","Frank"]}}} ->
"SELECT * FROM developer WHERE name IN ('Paul','Frank')"
{select,name,
{from,developer},
{where,{name,in,
{select,distinct,name,{from,gymnist}}}}} ->
"SELECT name FROM developer WHERE name IN
(SELECT DISTINCT name FROM gymnist)"
{select,name,
{from,developer},
{where,{name,in,
{{select,distinct,name,{from,gymnist}},
union,
{select,name,
{from,dancer},
{where,{{name,like,"Mikhail%"},
'or',
{country,'=',"Russia"}}}},
{where,{name,like,"M%"}},
[{order_by,{name,desc}},{limit,5,10}]}}}} ->
"SELECT name FROM developer
WHERE name IN (
(SELECT DISTINCT name FROM gymnist)
UNION
(SELECT name FROM dancer
WHERE ((name LIKE 'Mikhail%') OR (country = 'Russia')))
WHERE (name LIKE 'M%') ORDER BY name DESC LIMIT 5,10)"
Making ErlSQL was another lesson to me of the great expressiveness gained by the combination of of tuples, lists and pattern matching. It would be quite frustrating for me to use a language that doesn't have such semantics if I were ever forced to do so :)
In conclusion: if it looks like SQL and it acts like SQL, it must be... Erlang! :)
Update: There seems to be some confusion regarding the utility of ErlSQL, so I'll take another shot at explaining it. Many applications and libraries generate SQL queries programatically based on certain rules. ErlyDB is such library. Given a domain model and a set of relations, ErlyDB generates SQL queries for interacting with the data for this domain. The current implementation of ErlyDB (v0.1) does this by string concatenation, which is rather inefficient and error prone. ErlSQL facilitates writing SQL generation code in ErlyDB in a safe and efficient manner and by interacting directly with the semantics of the SQL language in Erlang. This is primarily why I made ErlSQL: I wanted to make SQL generation in ErlyDB more robust and elegant than string concatenation.
The second motivation is that for certain applications, the statements that ErlyDB generates automatically are not sufficient. Application developers often need to add their own WHERE framents and sometimes even write full queries to support the application requirements. I wanted to give developers the tools to write dynamic queries in a manner that's resilient to SQL injection attacks but without losing the full flexibility and familiarity of the SQL language and without stepping too far outside of Erlang.
Plus, it's neat to have the IDE indent your clauses and balance all your paretheses :)
Another note: Ulf Wiger pointed out to me on the mailing list that using Dialyzer, it may be possible to check the validity of the ErlSQL expressions in compile time. I haven't tried it, though.
Subscribe to:
Posts (Atom)